タイミーでバックエンドのテックリードをしている新谷(@euglena1215)です。
タイミーでは自律型 AI エージェント Devin を活用した開発を行っています。
Devin を効果的に活用する上で鍵となるのが、どのような「knowledge(知識)」を与えるかです。Devin を活用している各社で、試行錯誤が進められているのではないでしょうか。
もし Devin に一つだけ知識を与えて賢くするとしたら、何が最適でしょうか?
私は「会社固有の知識であり、かつ社員にとっては当たり前すぎて、AIに教えるという発想に至らない情報」が、AIの精度を向上させる鍵になるのではないかと考えています。
社員は知っているが Devin は知らない、そんな情報の代表格として思いついたのが「ユビキタス言語」です。実際に Devin にユビキタス言語を knowledge として教えてみたところ、抽象的な概念に対する理解度が向上する手応えがあったため、その TIPS を共有します。
また、Devin に教えるユビキタス言語が古くなっては逆効果です。そこで、ユビキタス言語の knowledge を半自動で更新する仕組みも作ってみたので、合わせて紹介したいと思います。
前提
私たちタイミーの環境における、2つの重要な前提について説明します。
1. Notion DBによるユビキタス言語の管理
タイミーでは、ユビキタス言語を Notion のデータベースで一元管理し、常に最新の状態に保つワークフローが確立されています。このデータベースには、以下の情報が含まれています。
- 表現(事業者向け): 企業向けの表現。企業向けとワーカー向けで指すものが同じでも表現が異なることがあるため分けています。 (例:求人を公開)
- 表現(ワーカー向け): ワーカー向けの表現。(例:募集を公開)
- 意味: 用語の意味
- NG表現: 誤って使われやすい用語例
- 実装の英語表記: 用語に対応する実装上のキーワード
- 備考: 用語を使用する際の注意事項
こちらに関して詳しく知りたい方は以下の記事をご覧ください。
2. TerraformによるDevin knowledgeの管理
次に、タイミーでは Devin の knowledge を Terraform で管理しています。
以下のような Terraform ファイルを記述することで、knowledge を登録できます。
resource "devin_knowledge" "this_is_knowledge_1" { body = <<EOT Pull Requestの説明には、.github/PULL_REQUEST_TEMPLATE.md のテンプレートをベースとして使用してください。 このテンプレートは、このリポジトリのすべてのPull Requestで使用する必要があります。 EOT name = "PR作成時のテンプレート利用" parent_folder_id = data.devin_folder.this_is_folder_name.id trigger_description = "foo リポジトリで Pull Request を作成する場合" }
こちらに関して詳しく知りたい方は、以下の記事をご覧ください。
実装
運用されているユビキタス言語の Notion DB と Devin の knowledge を Terraform で管理する仕組みが整備されているので、あとはそれらをつなぎこむだけです。
今回 Notion DB を CSV Export し、Terraform ファイルとして出力する Shell スクリプトを用意しました。
Shell スクリプトを生成するプロンプトは以下です。参考にしてみてください。
ユビキタス言語CSVからDevin KnowledgeのTerraformファイルを生成するスクリプト === 生成プロンプト === 以下の要件でユビキタス言語データベース(CSV)からDevin knowledgeのTerraformファイルを 自動生成するBashスクリプトを作成してください: 【目的】 - CSVに定義されたユビキタス言語をDevin Knowledgeに変換 - Devinが「お仕事リクエスト」→「offeringRequest」のような用語対応を理解できるようにする - 用語について質問された際に適切な検索指示を提供するナレッジベースを構築 【CSVファイル構造】 - ファイルパス: source/ubiquitous.csv - 列構成: 事業者向け表現, ワーカー向け表現, 意味・定義, 避けるべき表現, 実装上の英語表記, 備考 - 文字エンコーディング: UTF-8 - 引用符内の改行やカンマを含むデータあり(CSVパーサーで適切に処理が必要) 【処理要件】 1. CSVパーサー: Rubyの標準CSVライブラリを使用(引用符内改行問題を解決済み) 2. フィルタリング: 意味・定義がある全エントリを処理対象(実装向け表記の有無は問わない) 3. primary_expr決定: 事業者向け表現 → ワーカー向け表現 → "用語N" の優先順位 4. カウンター管理: 正しいインクリメントでリソース名重複を防止 5. 動的トリガー生成: 実装向け表記の有無でトリガー記述を分岐 【ナレッジ内容構造】 - タイトル: 「ユビキタス言語「XX」の用語対応ガイド:」(検索指示中心) - 【用語の定義】: 意味・定義の内容 - 【実装・開発時の検索キーワード】: * 実装向け表記がある場合: 「コードや実装: 「XX」」 * 事業者向け・ワーカー向け表現も追加 * 実装向け表記がない場合: 「概念・ドキュメント用語として使用」を追加 - 【避けるべき表現】: 避けるべき表現がある場合のみ - 【使用ガイダンス】: 実用的な使用方法の3項目リスト - 【補足情報】: 備考がある場合のみ 【トリガー記述】 - 実装向け表記あり: 「「XX」やその関連用語(YY等)に関する質問、実装、ドキュメント作成を行う場合」 - 実装向け表記なし: 「「XX」に関する質問やドキュメント作成を行う場合」 【出力ファイル】 - パス: envs/knowledge/ubiquitous_language.tf - 自動生成ヘッダー付き - terraform fmt で自動フォーマット - data.devin_folder.ubiquitous_language.id 参照(data.tfで定義済み) 【エラーハンドリング】 - CSVファイル存在チェック - 一時ファイル管理(trap使用) - 処理結果の統計表示 === 生成プロンプト終了 ===
上記によって生成した Shell スクリプトを実行すると、以下のような Terraform リソースが作成されます。
resource "devin_knowledge" "ubiquitous_language_53" { body = <<EOT ユビキタス言語「グループ限定公開」の用語対応ガイド: 【用語の定義】 グループ機能で作成したグループに所属する、特定のワーカーのみに求人を公開する機能 【実装・開発時の検索キーワード】 - コードや実装: 「limited」 - 事業者向け文書: 「グループ限定公開」 【使用ガイダンス】 この用語やその関連概念について質問・実装・ドキュメント作成を行う際は: 1. 上記の適切なキーワードで検索してください 2. 文脈に応じて事業者向け・ワーカー向け・実装用の表現を使い分けてください 3. 避けるべき表現は使用しないでください EOT name = "ユビキタス言語: グループ限定公開" parent_folder_id = data.devin_folder.ubiquitous_language.id trigger_description = "「グループ限定公開」やその関連用語(limited等)に関する質問、実装、ドキュメント作成を行う場合" }
更新手順
更新ステップは以下の通りです。
- Notion DB を CSV としてエクスポートし、Terraform を管理しているリポジトリに配置
- CSV から tf ファイルを生成する Shell スクリプトを実行し、Pull Request を作成
terraform plan&applyを実行
現状は手動での CSV エクスポートが必要ですが、 Notion API・MCP などを活用すれば、この更新フローの完全自動化も可能だと考えています。
Devin がどのように賢くなったか
このナレッジを与えたことで、Devin の振る舞いにどのような変化があったかを見ていきましょう。
まず、Devin が knowledge を適切に参照できているかを確認します。
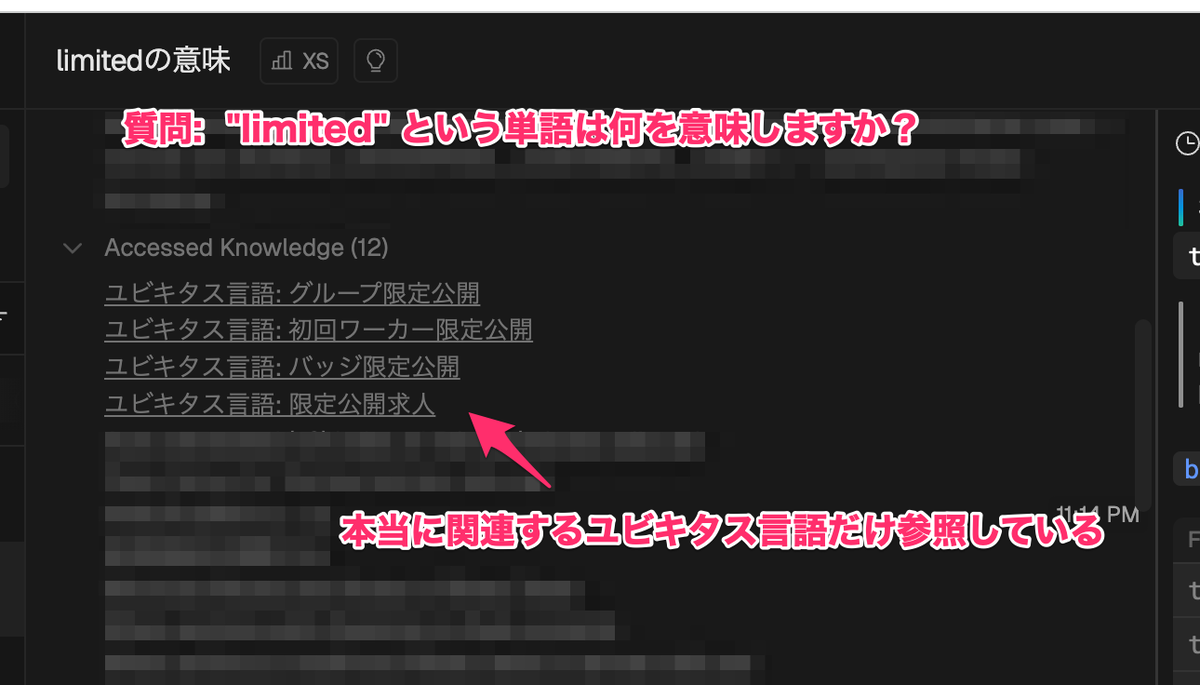
確認した結果、数あるユビキタス言語の中から、本当に関連するユビキタス言語のみを参照することに成功していました 🎉
次に、質問に対する回答の精度を比較します。上記のスクリーンショットにあるように、「“limited”という単語は何を意味しますか?」と質問してみました。
【ユビキタス言語 knowledge なしの場合】
「limited」は求人の公開範囲を制限する包括的な機能を表します。
【ユビキタス言語 knowledge ありの場合】
「limited」は求人の限定公開機能を指し、特定の条件を満たしたワーカーのみに求人を表示する仕組みです。
どちらも内容は似ていますが、よりタイミーの社員らしい、解像度の高い回答になったのは「ユビキタス言語あり」のパターンだと感じました。
ナレッジがない場合、Devin はコードベースを広範囲に検索・抽象化して回答を生成するためか、少し曖昧な表現に留まっています。一方、ナレッジを与えた後は、私たちが定義した「意味」に沿って、より的確な言葉で回答できるようになりました。
最後に
生成 AI ツールの進化によって、これまでチームの暗黙知とされてきたものを、いかに形式知として AI に与えていくかが、これまで以上に重要になってきています。
タイミーのエンジニアリング組織はフルリモートという特性もあり、以前からドキュメント化の文化が根付いています。今回の取り組みは、その文化をさらに一歩進めるものになりました。
これからも、AI との協業を前提とした開発体制の構築を進めていきたいと思います。