はじめに
この記事はTimee Product Advent Calendar 2025の25日目の記事です。
MLOpsエンジニアのtomoppiです。データエンジニアリング部 データサイエンスグループ(以下DSG)に所属し、ML/LLM基盤の構築・改善に取り組んでいます。
2024年10月にタイミーへジョインし、気がつけば1年あまりが経ちました。2025年はLLM/LLMOpsに奔走した1年で、PoCを実施した施策の本番導入や、LLMの可観測性・プロンプトマネジメントに取り組み、走りながら考え、考えながら走る日々でした。
そんな中で、ふと思うようになりました。「2026年、タイミーのLLM基盤はどうあるべきか?」
本記事は、その問いに対する私なりの答え——というより、夢と妄想です。この1年で見えてきた課題と、それを乗り越えるための構想を、できるだけ具体的に描いてみます。
2025年の振り返り
個人的な振り返り
まずは、私がこの1年取り組んできたことについて、簡単に触れさせていただきたいと思います。
年初時点では、社内でいくつかのLLM関連PoCが動いているフェーズで、まだMLOpsとしてのLLMへの関わりは薄い状態でした。一方で、DSG内ではLLMへの注目が高まり、キャッチアップを目的としたLLM勉強会が始まりました(この勉強会は現在も継続しています)。
その流れで、2月に「LLMOpsとは何か」をテーマに勉強会を開催し、評価手法やプロンプト管理、モニタリングなど、従来のMLOpsとは異なる論点をDSGで共有しました。
3月に入ると、PoC段階だったLLM機能を本番導入する動きが増え、「どう設計すれば安全かつ現実的に運用できるか」を一から詰めていくことになりました。この過程で得られた知見・経験は、LLMアプリケーション向けProduction Readiness Checklist執筆の動機になりました。
LLMOpsツール導入の検討も並行して行い、10月頃、LLMOps基盤としてDatadog LLM Observabilityの本格運用を開始しました。
「なんとなく動いている」から「ちゃんと運用できている」状態へ、徐々に進めている感覚がありました。
また、Datadog社からのお声がけで、Datadog LLM Observabilityを題材とした登壇の機会もいただき、実りの多い1年となりました。
LLMOpsとTeam Topologies
MLOpsチームは、Team Topologiesで言うCollaboration Modeで、データサイエンティストチーム(as Complicated Subsystem Team)やプロダクトエンジニア(as Stream-aligned team)と密に連携してきました。
AI施策ごとにMLOpsエンジニアがプロジェクトに参画し、初期の壁打ちからアーキテクチャ設計、実装まで伴走してきました。この進め方は、ナレッジが少なく不確実性が高い状況で、知見を素早く蓄積し、開発のアジリティを確保するうえで非常に有効でした。
一方で、この体制は長期的には持続しないことも見えてきました。
「AIを使いたい」という熱量が全社的に高まるほど、インフラやガバナンス整備待ちの「行列」が生まれ、結果としてビジネスのスピードを落としてしまいます。
同時に、LLM利用が拡大するにつれ、プロンプトインジェクションをはじめとするセキュリティ対策やコスト最適化、利用モデルの透明化といったガバナンスが、より重要になってくると考えています。
その規模になると、個別対応をずっと続けることは現実的ではありません。
2025年末の課題
整理すると、現状の課題は次の3つです。
- Agility(俊敏性の欠如)
- 検証環境構築のリードタイムが長く、高速な検証を阻害する状況になっています。
- LLM開発では「評価データの準備」「プロンプト変更→評価→改善の反復」「モデルの切り替え」「コスト見積(トークン/レイテンシ/単価)」など、環境以外にも反復のボトルネックが多く、施策の立ち上げや改善の速度を落としてしまいます。
- Scalability(拡張性の限界)
- LLM施策の需要増に対しMLOpsチームの供給体制が追いつかず、組織全体でのLLM施策がスケールしません。
- ボトルネックが「技術(インフラ)」ではなく「人(MLOpsチーム)」になっていることは、構造的な制約であり、このままではスケール上の限界に直面します。
- Governance(統制の分散/部分最適)
- 施策ごとに個別最適な判断・実装が積み上がり、環境や運用がサイロ化します。その結果、コスト配賦や利用実態の把握、セキュリティ対策、監査対応などがチームごとにバラバラになり、全社としての管理が難しくなっています。
2026年に目指したいタイミーのLLMOps
Collaboration ModeからX-as-a-Serviceへ
前述したような課題を乗り越え、LLM活用を全社的にスケールさせるために、2026年はMLOpsチームが個別のプロジェクトに入り込むのではなく、「セルフサービスで使えるプラットフォーム」を提供することを目指しています。Team Topologiesで言うX-as-a-Serviceへの移行です。
プロダクトチームが自律的にLLM機能を開発・運用できる基盤——これをUnified LLM Platformと呼ぶことにします。
「The Art of AI Maturity」とPlatform Engineering Maturity Modelへの接続
とはいえ、「本当にUnified LLM Platformとしての共通基盤は必要なのか?」という問いには答えておきたいところです。戦略的なフレームワークを参照しながら、その必要性を整理してみます。 そのフレームワークとして、The Art of AI MaturityとPlatform Engineering Maturity Modelを参照していきます。
The Art of AI Maturityから見たUnified LLM Platformの必要性
The Art of AI Maturityは、Accentureが提唱するAI成熟度を評価するフレームワークで、17のKey Capabilitiesを定義しています。タイミーでは、このフレームワークを全社的に参照しています。
Unified LLM Platformの構築は、以下の8つのKey Capabilitiesに対する実行施策となります。
| Key Capability | Unified LLM Platformとの関係 |
|---|---|
| #3. Proactive vs Reactive | 先行投資によるプラットフォーム整備により、市場ニーズ発生後の追随ではなく、先回りでAIオポチュニティを創出 |
| #4. Readily Available AI/ML Tools | セルフサービス化されたLLM開発環境により、開発者が環境準備で待たされない状態を実現 |
| #5. Readily Available Developer Networks | 統一インターフェースやオープンなアーキテクチャにより、OSSコミュニティとの連携を促進 |
| #6. Build vs Buy | 競争優位を生むコア領域(LLM features)は内製、基盤部分でのUtilityはSaaS/PaaS/OSSを活用するポートフォリオ戦略を実現 |
| #7. Platform & Technology | 推論基盤(マルチプロバイダー対応、統一API)、ガードレール(DLP/ポリシー/ツール実行制御)、可観測性(トレーシング/メトリクス)、評価、コスト管理をプラットフォームとして標準化し、安全で再現性のある運用を実現 |
| #13. Innovation Culture Embedded | 探索の自由度を高めるプラットフォームにより、日常業務に実験・学習サイクルを組み込む文化を促進 |
| #16. Responsible AI | 技術的統制(PIIマスキング、監査ログなど)により、倫理・法規制に適合したRAIプロセスを実現 |
| #17. Responsible AI — Change | RAI体制の継続的強化を、プラットフォームレベルで自動化・標準化 |
Platform Engineering Maturity Modelから見たUnified LLM Platformの必要性
次に、Platform Engineering Maturity Modelを参照してみます。 Platform Engineering Maturity Modelとは、プラットフォームエンジニアリングを5つの観点(Adoption、Interfaces、Investment、Measurement、Operations)で評価するフレームワークです。
これまでプロジェクト単位でのスピードを優先してきたため、プラットフォームとしての成熟度は「レベル1(暫定的)」であり、部分的に「レベル2(戦略的)」という評価になります。
0→1の立ち上げ期においては、この「都度対応」が最も機動力を発揮しました。しかし、1→10、10→100へとスケールさせるこれからのフェーズにおいては、かつての最適解(レベル1)が最大のアンチパターンになりつつあります。「レベル1だからダメ」なのではなく、「レベル1のやり方で戦えるフェーズは終わった」と認識しています。
2025年の振り返りで述べた課題や体制を踏まえると、現在のタイミーのLLMOpsは、各観点で以下のような状態にあると考えられます:
| 観点 | 現状 |
|---|---|
| Investment(投資) | プロジェクトごとの個別対応が基本で、MLOpsチームの部分的なタスクとして遂行している状況です。 |
| Adoption(採用) | LLMが必要なチームが散在する社内ナレッジをもとに施策を検討し、MLOpsチームも都度個別対応を行っていたため、標準的なプラクティスやポリシーが不十分な状態です。 |
| Interfaces(インターフェース) | これまではMLOpsエンジニアが伴走し、プロジェクトごとに最適な構成を提供してきました。部分的に共通化できている箇所もありますが、セルフサービスで利用できる統一インターフェースは整っていない状況です。 |
| Measurement(測定) | LLM基盤として指標は定義できておらず、収集もできていない状況です。 |
| Operations(運用) | これまではプロジェクトごとのリクエストに応じた柔軟な対応で素早く価値を届けてきましたが、モデルの利用状況や、更新対応は個別管理になっており、LLMライフサイクルを中央集権的に管理できていない状態です。 |
2026年に目指すのは、各観点でレベル3(スケーラブル)への移行です。これはチャレンジングな目標ですが、Unified LLM Platformの構築により実現を目指します:
| 観点 | 実現内容 |
|---|---|
| Investment | MLOpsチームがPlatform Teamとして明確な役割を持ち、LLM Platformのロードマップに基づく計画的な投資を実行していきます。 |
| Adoption | 「Golden Paths over Cages」 の方針により、「強制」ではなく「便利だから使われる」プラットフォームを実現。ドキュメント整備とオンボーディング(利用開始までの手順・ガイド)を含めたSelf-service化を推進し、プロダクトチームが自律的にLLM機能を開発・運用できる状態を目指します。 |
| Interfaces | 統一されたエンドポイントとOpenAI互換の単一API仕様を提供。認証・認可はインフラ層で透過的に実行され、開発者は意識不要。Observability by Defaultにより、追加実装なしで全リクエストのトレース・レイテンシ・コストを可視化し、セルフサービスで利用できるようにします。 |
| Measurement | LLM基盤のSuccess Metrics(標準指標)を定義し、必要な計装(テレメトリ/ログ/利用データ)を組み込みます。定期レビューにより、利用状況と改善効果を可視化し、意思決定と改善サイクルを回せる状態にします。 |
| Operations | どのサービスがどのモデルを利用しているのかを中央集権で管理し、モデルの非推奨対応や新規モデルのロールアウト統制を取れる状態にします。加えて、Migration手順、責任分界(責任共有モデル)、ロールバック戦略を標準プロセスとして整備します。 |
実現に向けたエンジニアリング
ここからは、どのようにUnified LLM Platformを実現するのか、エンジニアリング観点で整理していきます。
「探索の自由度」・「運用時の信頼性」・「技術的統制」
プラットフォームを設計するにあたり、特に重視したい要求を3つに整理しました。
1. 探索の自由度(Freedom of Exploration)
- 「データサイエンティストやプロダクトエンジニアが、面倒な環境構築なしに、アイデアを即座に試せる環境」 を実現したいです。
LLM開発は「試行錯誤」がすべてです。エンジニアだけでなく、PMやビジネスサイドのメンバーもプロンプトを直接触れられることが、開発速度に直結します。
この要求を満たすため、以下の要素が重要です。
- モデルの切り替え(Model Agnostic)
- 「Geminiで試したけど、AnthropicやBedrockだとどうなる?」をコード変更なしで、設定の切り替えだけで素早く試せること。
- 統一インターフェース
- プロバイダーごとに異なるAPI仕様(OpenAI / Azure / Bedrock / Vertex AIなど)を意識せず、統一されたSDK/APIで呼び出せること。
- プロンプトのバージョン管理とプレイグラウンド
- Gitのように「v1.2のプロンプト」と「v1.3のプロンプト」をGUI上で比較実行できる環境。エンジニアに依頼せずとも、画面上でパラメータを調整して挙動を確認できること。
- 評価駆動開発(Eval-driven Development)のための環境
- オフライン評価における実験管理やLLM-as-a-judgeなどを、Day1から行えること。
- Open-weight Modelsの活用
- 必要なユースケースでは、GKE上のvLLMなどでOpen-weight Modelsを扱える選択肢を残すこと。
2. 運用時の信頼性(Operational Reliability)
- 「確率的なLLMを、確定的なエンタープライズシステムとして振る舞わせるための安定化機構」 が必要です。
PoCでは許されても、本番環境では「APIが落ちていました」「遅すぎます」は許されません。
この要求を満たすため、以下の要素が重要と考えています。
- リトライとフォールバック(Fallbacks)
- プロバイダー障害時に別経路へ切り替えたり、高性能モデルがタイムアウトしたら高速なモデルで再試行したりする冗長化構成。
- ただし、フォールバックは「評価で許容できる」と確認できた組み合わせに限定。(挙動差分が大きいと品質事故につながるため)。
- スマートキャッシング(Caching)
- 同一リクエストにはキャッシュから応答し、レイテンシ短縮とコスト削減を両立。将来的にSemantic Cacheも検討。
- レート制限と公平性
- 一部のヘビーユーザーがトークンを使いすぎて他のサービスに影響を与えないよう制御できること。
- オブザーバビリティ
- 開発者がモニタリング環境の構築を意識せず、モデルの性能やリソース使用状況を確認できること。
3. 技術的統制(Technical Governance)
「組織としてリスクをコントロールし、野良AIや青天井のコストを防ぐためのガードレール」を整備したいです。
この要求を満たすため、以下の要素が重要と考えています。
- PII/機密情報のマスキング (Redaction)
- クレジットカード番号、メールアドレスなどがプロンプトに含まれていたら、LLMに送信する前に自動でマスキングする機能。
- プロンプトインジェクション対策(Prompt Injection Mitigation)
- 入力/出力のフィルタリング(疑わしい指示の検知・遮断、システムプロンプトや機密情報の漏洩防止など)と、コンテンツポリシー(許可/禁止の基準)をプラットフォーム側で標準化する。
- Tool Use(外部API呼び出し、DB参照、チケット発行など)を行う場合は、ツールのAllowlist化・引数検証・権限境界の設計などにより「実行制御」を行い、必要に応じてサンドボックス(隔離環境)で安全に実行する。
- 認証方式の統一化
- 全てのLLMリクエストをLLM Gatewayを通すことで、認証方式を統一化し、プロジェクト固有で認証部分を行う必要性をなくす。
- コストの予算管理 (Cost Budgeting)
- 「プロジェクトAは月額◯◯円まで」といったキャップを設定し、超過しそうになったらアラートを出す仕組み。
- 監査ログ (Audit Logs)
- 「誰が」「いつ」「どんなプロンプトを」「どのモデルに」投げたか追跡可能にすること。
- ここは強い統制になる一方、ログの取り扱い(PIIの扱い、保持期間、閲覧権限、暗号化、マスキング後のみ保存など) も同時に設計対象。
プラットフォームの構成イメージ
これらの要件を同時に満たすために、AI Gateway(LLM Gateway) というアーキテクチャパターンを中心に据えることを検討しています。
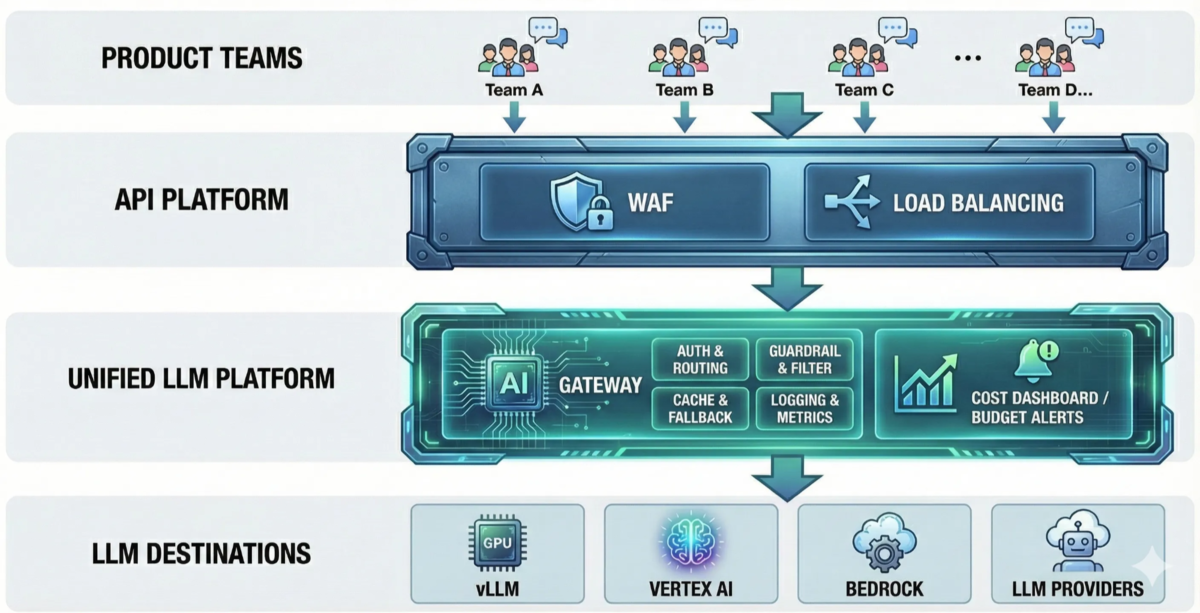
アプリケーションとLLMプロバイダーの間に「ゲートウェイ」を挟むことで、開発者は自由にAPIを呼び出せます。一方で、裏側では自動的にログが取られ、セキュリティチェックが走り(統制)、キャッシュやリトライが効く(信頼性)という構成です。
設計原則
プラットフォームを構築・運用していく上で、以下の原則を大事にしたいと考えています。これらは Platform Engineering、セキュリティ、SRE / Observability、LLMOps の各分野から学んだものです。
| 原則 | 概要 |
|---|---|
| Platform as a Product | プラットフォームを「社内向けプロダクト」として捉え、利用者(プロダクトチーム)の体験を最優先に設計する。「インフラを提供する人」ではなく「開発者という顧客にプロダクトを届ける人」としてのマインドセットを持つ |
| TVP(Thinnest Viable Platform) | 初期スコープは「ガバナンスと可観測性」を解決する純粋なLLM APIプロキシに絞る。RAGやTool Useは後から。まずは「安全で、誰が使ったか、いくらかかったかがわかるAPI」を全社に民主化する |
| Golden Path の提供 | 「推奨される使い方」を明確にし、その道を歩めば自然とベストプラクティスに沿える状態を作る。自由度は残しつつも、迷わないための道標を用意する |
| Secure by Default | LLMはプロンプトインジェクションやPII流出など従来とは異なるリスクがあるため、ガードレールをデフォルトで有効にした状態を標準とする。「セキュリティを意識しなくても安全」な状態を作る |
| Observable by Default | LLMは確率的に動作するため、入出力の追跡なしには改善のポイントが見えない。特別な設定なしで自動的にトレーシングとメトリクス収集が行われる状態を目指す |
| Eval Driven(評価駆動) | LLM開発ではリグレッションが頻繁に発生するため、「感覚」ではなく「評価」で改善を確認する。評価データセットの整備、CI/CDへの評価組み込み、LLM-as-a-Judgeによる自動スコアリングを開発フローに組み込む |
アーキテクチャ設計
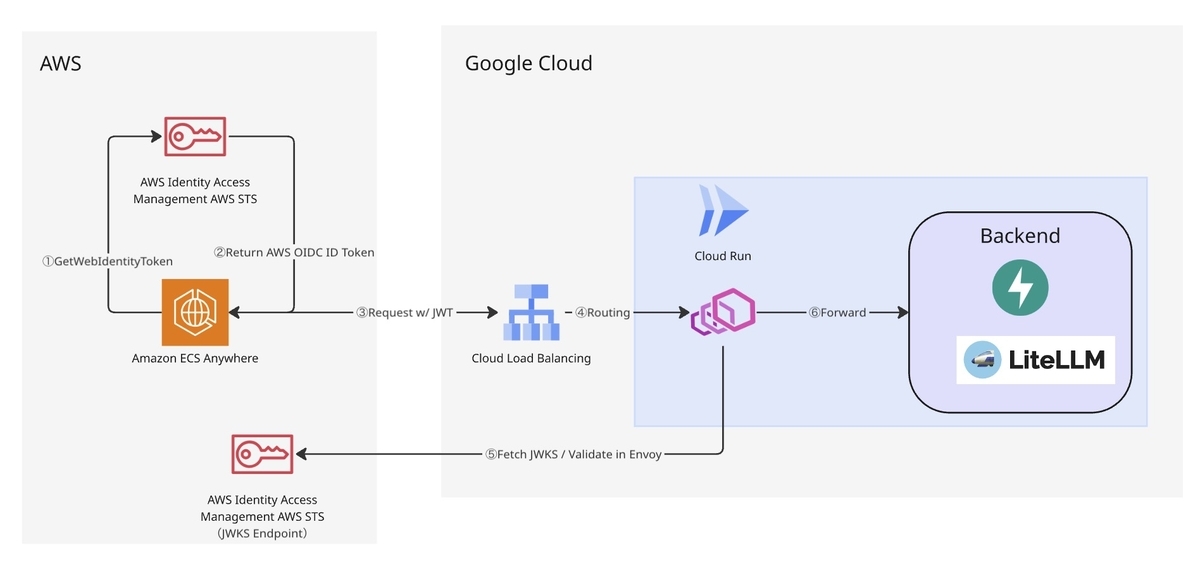
現在、初期検証で構築しているアーキテクチャは下図のようになっています。
技術選定
AI Gateway
まずはAI Gateway(LLM Proxy)の技術選定から着手しました。ここで満たしたい要件は、ざっくり言うと次のとおりです。
- マルチプロバイダー対応: Vertex AI / AWS Bedrock / GKE上のvLLM(セルフホスト)を同じ入口で扱えること
- 認証: LLMプロバイダー側へのキーレス認証(OIDCなど)と、クライアント向けのVirtual API Key
- トラフィック制御と信頼性: リクエスト数・トークン数ベースのレート制限、フォールバック、ストリーミング
- 統一インターフェース: OpenAI互換APIなどのスキーマ正規化、Embeddingsのサポート
- オブザーバビリティとコスト: OpenTelemetry連携、コスト追跡(チーム/キー単位の配賦)、(将来的な)セマンティックキャッシュ
- ガードレール: PII/DLPのマスキング(Redaction)を含む入力/出力のフィルタリングに加え、プロンプトインジェクション対策(ポリシー、検知/遮断、必要に応じたTool Useの実行制御)
10個強のツール(LiteLLM Proxy / Envoy AI Gateway / APISIX / Kong / Portkey.ai など)を調査した結果、現時点では LiteLLM Proxy が要件を最も素直に満たせそう、という結論になりました。
一方で、Envoy AI Gateway もKubernetesネイティブで魅力的です。将来的に本格的な本番運用(GitOps前提の運用、より厳格なトラフィック制御、低レイテンシ)に寄せるなら有力候補です。しかし現段階では、初速を優先して LiteLLM +(認証を担う)Envoy Sidecarの構成から始めるのが現実的だと感じています。
LLM Observability Tool
現在利用しているDatadog LLM Observabilityは、プラットフォームでも引き続き中核の可観測性基盤として活用する想定です。AI Gateway 経由の呼び出しを起点に、レイテンシやエラー、トークン使用量などを一貫して可視化し、運用改善や評価(Eval Driven)に繋げます。
Envoy Sidecar vs Service Mesh
Cloud Runのマルチコンテナ機能で、Envoy → Backend にする必要があるかどうかについては、代替案としてService Mesh(Istio・Cloud Service Mesh)が考えられます。
しかし、現状Service Mesh構成ではなく、この取り組みのために0からService Meshを構築することは、TVPの考え方に反します。そのため、Envoy Sidecarを採用することにしました。
AWS → GCPのキーレス認証
クロスクラウド連携で悩ましいのが、 AWS → GCP の認証です。従来の Workload Identity Federation だと、GCP側のSTSを呼び出してアクセストークンを取得する必要があり、実装・運用の負担が大きくなりがちです。
そこで最近登場した、AWS IAM Outbound Identity Federation を使って、AWS STSが発行するJWTを、Cloud Run前段のEnvoyで直接検証する方式を採用することにしました。
おわりに
ここまで読んでいただきありがとうございます。
この構想には多くの不確実性があり、自由と統制のトレードオフとも向き合い続けることになると思います。「夢妄想」と銘打ったとおり、すべてが計画どおりに進む保証はありません。
それでも、「安全に、再現性を持ってLLMを活用できる状態をつくる」という軸だけはブレずに、2026年はタイミーのLLM基盤を前に進めていきたいと思います。
来年のアドベントカレンダーで、「あの夢妄想、現実になりました」と報告できることを目指して。
タイミーのMLOps・LLMOpsって面白くなりそうと思ってもらえた方はぜひ、お話ししましょう!