こんにちは、アナリティクスエンジニアのhatsuです。
普段はデータエンジニアとアナリティクスエンジニアからなるDREという組織に所属し、データ基盤を整えたり、dbtを使ったデータウェアハウスの開発などをしています。
本記事では、私が所属するDREで最近取り組んだ、ダッシュボードなどのデータアウトプットの管理についてご紹介してみようと思います。
なお、この記事は Timee Advent Calendar 2025 シリーズ2の1日目の記事です。
今日から毎日3本ずつ記事が投稿されますので、ぜひ他の投稿もご覧ください!
背景と課題
タイミーでは社内でいろんなメンバーがいろんなデータを日々活用していて、社内のデータアウトプットも数え切れないほど存在しています。
これらのデータアウトプットはコード管理やクエリのレビューをしていないものがほとんどで、意図せず誤ったクエリが重要なデータとして活用されてしまうことも度々ありました。
さらに、「昔は使っていたけど今はもう使っていない」、あるいは「作ったけど結局使わなかった」といった、古くてもう使われていないようなデータアウトプットも残り続け、データが更新され続けている現状があります。
どのデータアウトプットが今使われているのか、誰がそのデータアウトプットの責任者なのか、どういった品質が保証されているのかなど、データアウトプットに関する情報がこれまで管理できていないことがチーム、ひいてはデータを活用する会社全体の課題でした。
そこで、データアウトプットそれぞれに対して設定する“信頼性レベル”を定義し、その“信頼性レベル”に応じてデータアウトプットを管理していく取り組みを始めてみることにしました。
チームで定義した“信頼性レベル”とは
チームで定義した“信頼性レベル”というのは、データアウトプットの保守運用のために求められる要件と、それによって得られるデータアウトプットの保証内容を定義したものです。
現状、アウトプットの利用目的などに応じて、Trusted・Verified・Provisional・Adhocの4つのレベルに分けて定義しています。
それぞれのレベルで、保守運用をするために満たすべき要件と、それを満たすことで私たちDREが保証する保守運用の水準、例えば障害時やソースデータに破壊的変更が加えられるときの対応方針などを下記のように設定しています。
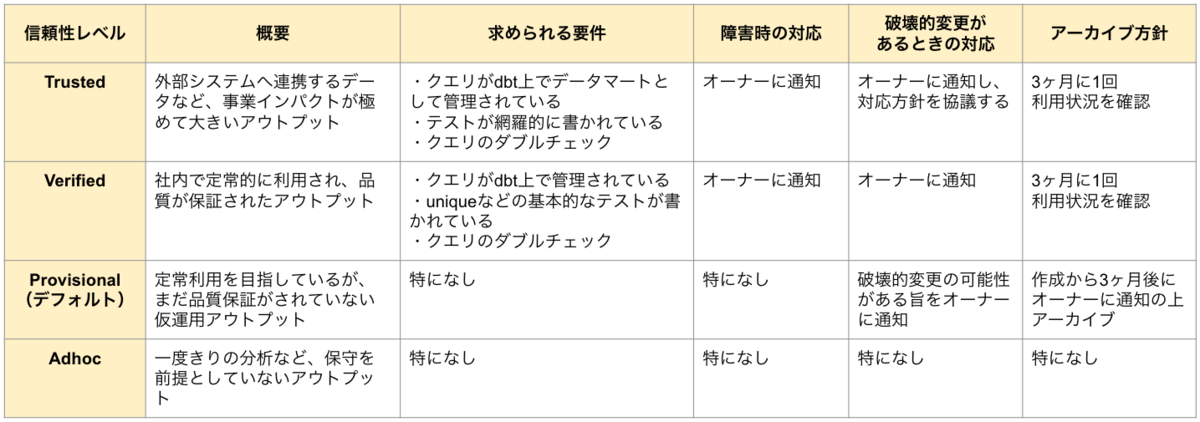
表の一番右にアーカイブの方針が書いてあり、使われなくなったデータアウトプットはアーカイブされていくような運用にしています。
ここで言うアーカイブとはデータアウトプットの即時削除ではなく、ゴミ箱に入れられている、もしくはクエリのスケジュール実行が停止されている状態を指していて、まだ利用されているデータアウトプットが誤ってアーカイブされた場合にも復元可能な状態になっています。
各データアウトプットがどの信頼性レベルに設定されているかは、dbt exposureを用いて下記のようなyamlファイルで管理しています。
version: 2 exposures: - name: {{ConnectedSheetタイトル}}_{{ConnectedSheetId}} label: {{ConnectedSheetId}} type: dashboard config: tags: - PEOPLE_WITHIN_DOMAIN_WITH_LINK - spreadsheet meta: creator: test@example.com owner: test@example archived: false archived_at: null reliability_level: Provisional created_at: '2025-11-20T17:00:00+09:00' deprecated_at: '2026-02-20T17:00:00+09:00' visibility: PEOPLE_WITHIN_DOMAIN_WITH_LINK output_type: spreadsheet url: https://docs.google.com/spreadsheets/d/{{ConnectedSheetId}} owner: name: test@example.com email: test@example.com depends_on: - ref('hogehoge_model') - ref('foo_bar_model') - ref('chomechome_model')
例えば、上記のyamlファイルには reliability_level: Provisional と書かれていることから、この例に書かれているデータアウトプットは信頼性レベルProvisionalの水準で保守運用されていることがわかります。
初めは信頼性レベルがデフォルトのProvisionalのものとして自動でexposureが登録され、そこからデータアウトプットのオーナー(利用者)が利用目的に応じて適宜信頼性レベルを変更します。
dbt exposureを用いたデータアウトプットの自動登録と管理については、以前こちらの記事でも紹介していますのでぜひご覧ください!
信頼性レベルを運用することで期待される効果
このような信頼性レベルを運用することで、DREにもデータアウトプットのユーザーにも嬉しい効果があると考えています。
- 膨大な数のデータアウトプットの中からDREが保守するべき対象が明確になり、障害発生時のユーザーへの連絡などもスムーズに行えるようになる
- データアウトプットのユーザーは、自分が利用しているデータアウトプットに障害や破壊的変更の影響があるかを、通知によって把握できるようになる
- もう使わないデータアウトプットを適切にアーカイブすることで、メンテナンスされていない古いデータアウトプットをユーザーが誤って使ってしまうことを避けられる
信頼性レベル運用の現状と今後
この信頼性レベルの仕組みは、まだ会社全体に展開したものではなく、一部のメンバーとお試し運用中のものです。
お試し運用を通して運用の改善や修正を行いながら、将来的に会社全体で信頼性レベルを運用できるようにしていくことを目指しています。
また、障害時や破壊的な変更がある場合の通知は現状手作業で行なっていたり、信頼性レベル変更時に求められる要件を満たすための作業が大変だったりと、まだまだ信頼性レベルの運用コストが高い状態なので、自動化できるところは自動化して運用工数を下げていくことで、持続的に運用できる仕組みを作っていきたいと考えています。
最後に
12月17日(水)に「第2回データ分析現場のリアルな知恵と工夫」というオフラインイベントに登壇させていただきます。
本記事でもご紹介した信頼性レベルの運用の話をしようと思っていますので、ご興味がある方はぜひご参加ください!