※Timeeのカレンダー | Advent Calendar 2023 - Qiitaの12月13日分の記事です。
はじめに
こんにちは
okodoooooonです
dbtユーザーの皆さん。dbtモデルのbuild、どうやって分割して実行してますか?
何かしらの方針に従って分割をすることなく、毎回全件ビルドをするような運用方針だと使い勝手が悪かったりするんじゃないかなあと思います。
現在進行中のdbtのもろもろの環境をいい感じにするプロジェクトの中で、Jobの分割実行について考える機会があったので、現状考えている設計と思考を公開します!(弊社は一般的なレイヤー設計に従っている方だと思うのでJob構成の参考にしやすいと思います)
この辺をテーマに語られていることってあんまりないなあと思ったので、ファーストペンギンとして衆目に晒すことで、いい感じのフィードバックをもらえたらなーと思ってます。
弊社のデータ基盤全体のデザインについて把握してからの方が読みやすいと思うので、そちらをご覧になりたい方はこちらの記事からご覧ください。
これまでの弊社のデータ更新周りについて
これまでの弊社のdbt Job設計の概念図を作るとしたらこんな感じになります。

- 走っているクエリがフォルダ単位/モデルファイル単位などバラバラな粒度で実行されている
- リネージュを意識したJobの走らせ方になっておらず更新頻度の噛み合わせが悪い
- 明確なルールがないので意図しないタイミングで同じモデルがビルドされたりする
- 明確なルールがないのでビルドから漏れているモデルがひっそり存在している
dbtコマンドで示すとこんな具合のカオス感
dbt build --select models/path_to_model_dir1/model1-1.sql dbt build --select resource_name dbt build --select models/path_to_model_dir2/model2-1.sql dbt build --select models/path_to_model_dir3 ....
改善のための試行錯誤 v1
- レイヤーごとにtagを付与して以下のようなビルドコマンドが走らせられるようにしました。
dbt build --select tag:staging_layer dbt build --select tag:dwh_layer dbt build --select tag:dm_layer
- 更新頻度tagの概念を設計して、以下のようなビルドコマンドを走らせられる構成を検討しました。
dbt build --select tag:hourly_00 # 毎時00分にビルドするものに付与するタグ dbt build --select tag:daily_09 # 毎日9時にビルドするものに付与するタグ
これらの設計をしてみて、レイヤー単位でJobを走らせることを可能にできたのと、更新頻度をdbt上で管理可能な形にはできました。
しかし、ユーザーのデータ更新ニーズに基づいたJob設計になっていないことから、ユーザーニーズベースでのJob管理方針の検討を進めました。
データ活用ユーザーのデータ更新ニーズの整理
弊社のレイヤー設計とデータ活用ユーザーのアクセス範囲は以下のような形になります。

- アナリストはステージング層以降の層に対するアクセス権を保持していますが、現状アナリスト業務はモデリング済みテーブルではなく、3NFテーブルに対するクエリを作成する作業が支配的です(モデリング済みテーブルの拡充とその布教をもっと頑張りたい)。
- データ組織外の社内ユーザーはデータ組織が作成したアウトプットを通して分析基盤のデータを活用できるような状態になっています。
- ※弊社内ではデータ組織以外のユーザーにBigQueryのクエリ環境を開放しておらず、LookerやLookerStudioなどのアウトプットを経由して社内データにアクセスする状態にしています。
それぞれの層ごとの現在顕在化しているデータ更新ニーズを整理すると以下のようになります。

- アナリストと野良アウトプットによる「ステージング層のなるはや更新ニーズ」
- アナリストのアドホッククエリ
- 分析要件は予測ができず、要件次第では最新のデータが必要となるため、なるべく早く更新されることが期待されます。
- マートから作成されずステージングテーブルから作られるアウトプット
- 更新頻度ニーズのすり合わせなく作られて提供されるものも多く、要件次第では最新のデータが必要となるため、なるべく早く更新されることが期待されます。
- アナリストのアドホッククエリ
- データ活用ユーザーによる「アウトプット更新ニーズ」
- データ活用ユーザーに提供するデータマート経由のアウトプットは更新頻度を擦り合わせられているものだけになっている(今はまだ数が少ないだけだが)ため、hourly,daily,weekly,monthlyなどの頻度ごとの更新設計が可能となっています。
- 例えば弊社のよく使われるLooker環境はhourlyの頻度で更新が要求されています。
単純なジョブ設計をしてみる
単純なジョブ実行案① ステージングなるはや更新プラン
ソースシステムごとのデータ輸送完了後にそのソースシステムを参照しているモデルを全てビルドするプラン
- コマンド例
- salesforceのデータ輸送完了後のコマンド:
dbt build --select tag:salesforce_source+dbt build --select models/staging/salesforce+
- アプリケーションDBのデータ輸送完了後のコマンド:
dbt build --select tag:app_source+dbt build --select models/staging/app_db+
- salesforceのデータ輸送完了後のコマンド:
- 実装方法
- airflowなど何かしらのオーケストレーションツールで転送完了をトリガーに下流一括ビルドのコマンドを実行する必要がある。
この場合の更新ジョブを概念図に表すと以下のようなものになると思います(上流から下流へのビルド時のデータリネージュを黄色の三角形で表現しています)。
 メリデメをまとめると以下のようになるかと思います
メリデメをまとめると以下のようになるかと思います
- メリット
- 下流が全てビルドされるのでビルド漏れが発生しない。
- 常にモデルの鮮度が最新になる = アナリストのstaging最新化ニーズは満たせている
- デメリット
- 更新がそこまで不要なモデルに対してまでビルドが実行される。
- BigQueryのクエリ料金が高額になる
単純なジョブ実行案② ユーザーニーズに合わせるプラン
ユーザーのデータ更新ニーズに合わせて更新頻度をアウトプットごとに設定。更新ニーズの頻度ごとに最新化されるようなプラン
- コマンド例
- 1時間おきにビルドされて欲しいアウトプットを更新するコマンド:
dbt build --select +tag:hourly - 1日おきにビルドされて欲しいアウトプットを更新するコマンド:
dbt build --select +tag:daily
- 1時間おきにビルドされて欲しいアウトプットを更新するコマンド:
この場合の更新ジョブを概念図に表すと以下のようなものになります(下流から上流へのビルド時のデータリネージュを赤色の三角形で表現しています)。
 メリデメをまとめると以下のようになります。
メリデメをまとめると以下のようになります。
- メリット:アウトプットの更新頻度が最適化される。
- デメリット
- stagingのモデル作成の重複が発生する。
- 出力ニーズが存在しないstagingテーブルなどがビルド対象から漏れてしまう
ではジョブ分割をどのように設計するか
- ステージングなるはや更新に合わせてリネージュの上流から実行すると下流で無駄なビルドが発生してしまう。
- ユーザーニーズベースでリネージュの下流から実行すると上流で無駄なビルドが発生してしまう。
この二つの問題の折衷案を考える必要があると考えました。
現状のジョブ実行案
更新ジョブの概念図は以下のようなものになります(上流から下流へのビルド時のデータリネージュを黄色の三角形、下流から上流へのビルド時のデータリネージュを赤色の三角形で表現しています)。
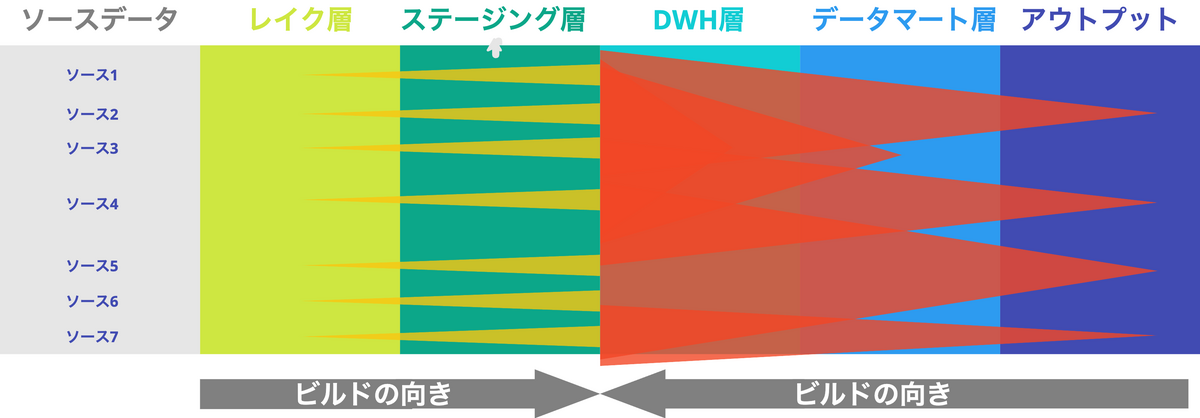
- ソースデータ ~ ステージング層のビルド
- ソースデータが連携されたらステージング層までを下流に向かってビルド
- コマンド:
dbt build --select tags:source_a+ --exclude tags:dwh_layer tags:dm_layer
- DWH層~アウトプットの間のビルド
- ステークホルダーと定めた更新頻度に合わせて上流に向かってビルド
- コマンド:
dbt build —select +tags:daily_00_00 —exclude tags:staging_layer tags:datalake_layer
こうすることで、ステージング層までは常に可能な限り最新化されつつ、アウトプットは要件ごとに更新頻度が最適化された状態となります。
ただ、DWH層やデータマート層に多少のビルドの重複は発生してしまいますが、そこは許容しています。
本当はこうしたい案
 アナリストがモデリング済みのDWH層を使うことが常態化するような世界観になってくると、上図のように「レイク~DWHまでは最新鮮度」「それ以降はユーザーニーズベースで更新」って流れがいいのかなと思っています。
アナリストがモデリング済みのDWH層を使うことが常態化するような世界観になってくると、上図のように「レイク~DWHまでは最新鮮度」「それ以降はユーザーニーズベースで更新」って流れがいいのかなと思っています。
また source_status:fresher+などのstate管理をうまく使って、更新があったものだけをビルドするような方式を模索していきたいです。
おわりに
dbtの環境リプレイスとともにこのJob設計も実戦投入しようと考えているので、想定していなかったデメリットが発覚したり、改善点が見つかったら改善していこうと思います!
弊社データ基盤でもストリーミングデータが取り扱えるようになったので、そのデータの使用が本格化すると ストリーミング✖️バッチ のJob構成などを考える必要があり、まだまだ俺たちの戦いはこれからだ。と思います
ていうかみなさんどうやって分割して実行してるの!!!教えてほしすぎる
We’re Hiring
タイミーのデータ統括部はやることがまだまだいっぱいで仲間を募集しています!興味のある募集があればこちらから是非是非ご応募ください。