この記事は Timee Advent Calendar 2023 シリーズ 3 の12日目の記事です。
はじめに
DREグループでデータエンジニアをやっている西山です。
今回は、データ転送まわりの運用自動化について書きます。
タイミーのアプリログが分析できる状態になるまでのリードタイムが長く、効果検証や意思決定に遅れが出ていた問題に対して、dbtに関連する運用を自動化することで改善しました。
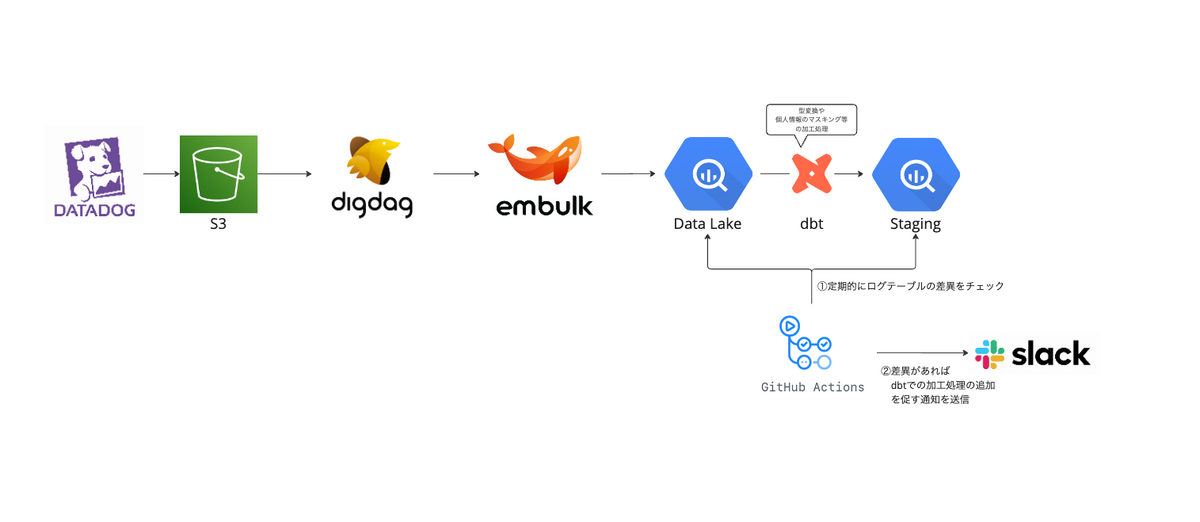
タイミーでのアプリログの転送について
タイミーではS3に貯まったサーバーログを定期的にデータ基盤(GCPのBigQuery)へ転送しており、ログがLake層へ追加されるとdbt(data build tool)によって型変換等の加工処理がなされてStaging層へと転送されます。
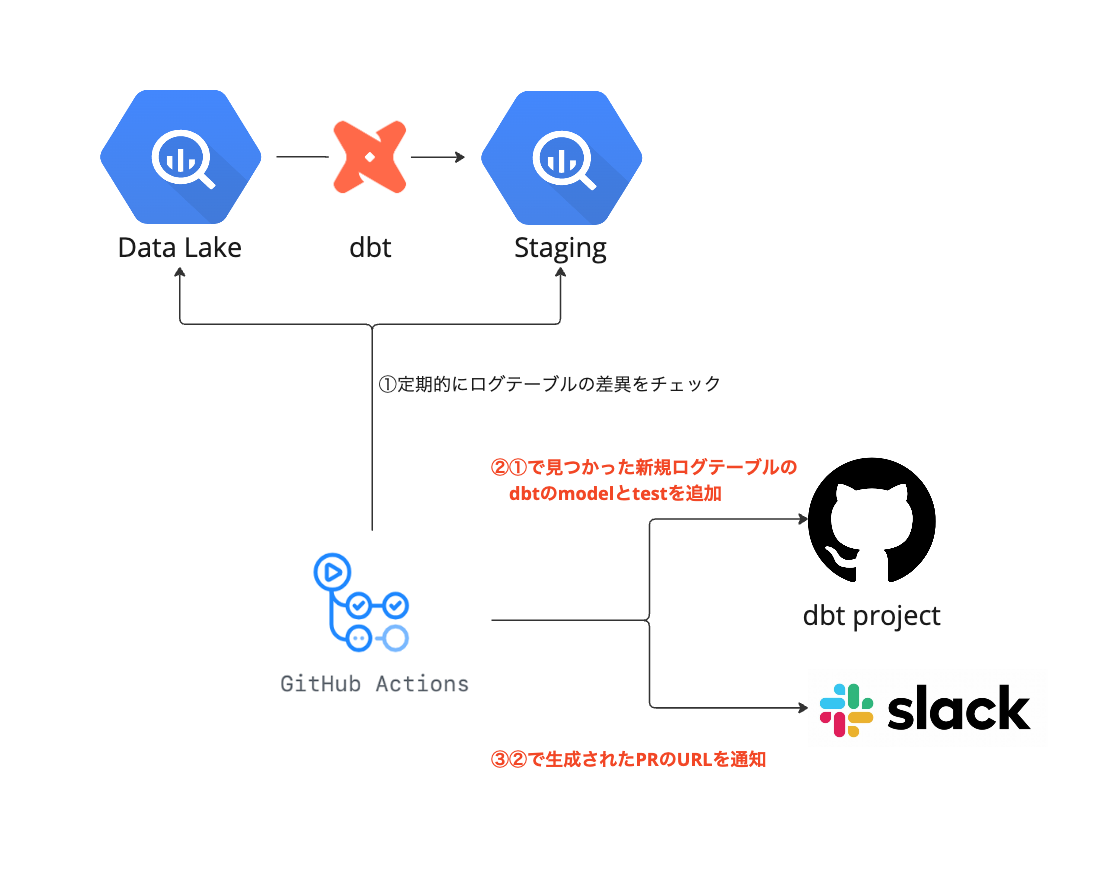
アプリの機能追加によって新しいログテーブルが追加された場合、dbtの処理追加が必要になるため、GitHub Actionsで定期的にLake層とStaging層でログテーブルの差異をチェックし、Lake層に新しく追加されたテーブルがあれば処理追加を促す通知をslackへ送信していました。
通知を確認したら、以下の対応を行います。
- 新しく追加されたテーブルのスキーマを確認
dbtでmodelを作成
- 他のログテーブルのmodelをコピー
- カラム名やキャスト処理を修正
{{ config( alias={{ テーブル名を書く }} ) }} {% set column_lists = [ {{ カラム名を書く }}] %} {{ production_logs_template({{ テーブル名を書く }}, column_lists) }} , result_record AS ( SELECT {{ カラム名を書く }}, dre_transfer_at, ROW_NUMBER() OVER (PARTITION BY {{ カラム名を書く }}) AS row_number FROM records ), stg_record AS ( SELECT {{ 各カラムの変換処理を書く }}, FROM result_record WHERE row_number = 1 ) SELECT *, {{ set_record_exported_at(column_lists) }} AS dre__record_exported_at, FROM stg_recordチーム内レビュー
- dbtのジョブを実行してStging層にもテーブルを追加
基本的には通知を確認次第、上記の対応を行う方針でしたが、他に優先度の高い障害対応や他チームからの依頼があると後回しになってしまうことも多く、1週間以内にStaging層へ新規ログテーブルを転送する取り決めとなっていました。
しかし、これだとログが分析できるようになるまでのリードタイムが長く、プロダクト開発チームの効果検証や意思決定に遅れが出てしまいます。
そこで、今回はこのリードタイムの短縮を目指すことにします。
実装案
アプリのログに関しては、dbtで実装する加工処理の内容がほぼ決まりきっているため、modelの追加が自動化できそうです。
(例)
- 末尾にidが付くカラムはINT型へキャスト
- 末尾にatが付くカラムはJSTのDATETIME型へキャスト
これまで新しいログテーブルを検知していたGitHub Actionsのツール内で、dbtのmodel追加のPRを生成することにします。
実装してみた
大まかにやったこととしては以下の通りです。
- GitHub AppsによるAPIリクエストの準備
- pythonで書かれている監視ツールの修正
GitHub AppsによるAPIリクエストの準備
今回はログテーブルの監視ツールとdbtプロジェクトが格納されているリポジトリが異なったため、GitHub Appsを作成してAPI操作ができるようにします。
- 以下の手順に沿ってAppを作成 https://docs.github.com/ja/apps/creating-github-apps/registering-a-github-app/registering-a-github-app
- Appの秘密鍵を取得 https://docs.github.com/ja/apps/creating-github-apps/authenticating-with-a-github-app/managing-private-keys-for-github-apps
- 認証に必要な
INSTALLATION_IDを生成 https://docs.github.com/ja/apps/creating-github-apps/authenticating-with-a-github-app/authenticating-as-a-github-app-installation#generating-an-installation-access-token - 3.で生成した
INSTALLATION_IDを使ってinstallation access tokenを発行 今回は監視ツールに以下のクラスを追加しました。
import json import os from datetime import datetime, timedelta import jwt import requests class GitHubAppTokenManager: def __init__(self) -> None: self.GITHUB_APP_ID = os.environ.get("APP_ID") self.GITHUB_APP_PRIVATE_KEY = os.environ.get("APP_PRIVATE_KEY") self.GITHUB_APP_INSTALLATION_ID = os.environ.get("APP_INSTALLATION_ID") def _generate_jwt(self) -> str: PEM = ( self.GITHUB_APP_PRIVATE_KEY.replace("\\n", "\n") if self.GITHUB_APP_PRIVATE_KEY is not None else None ) utcnow = datetime.utcnow() alg = "RS256" payload = { "typ": "JWT", "alg": alg, "iat": utcnow, "exp": utcnow + timedelta(seconds=60), "iss": self.GITHUB_APP_ID, } return jwt.encode(payload, PEM, algorithm=alg) def _generate_jwt_headers(self) -> dict: jwt_token = self._generate_jwt() return { "Authorization": f"Bearer {jwt_token}", "Accept": "application/vnd.github.machine-man-preview+json", } def _fetch_access_token(self) -> str: url = f"https://api.github.com/app/installations/{self.GITHUB_APP_INSTALLATION_ID}/access_tokens" response = requests.post(url, headers=self._generate_jwt_headers()) response.raise_for_status() return json.loads(response.text).get("token") def generate_token_header(self) -> dict: token = self._fetch_access_token() return { "Authorization": f"token {token}", "Accept": "application/vnd.github.inertia-preview+json", }
dbtのmodelとtestの生成処理追加
GitHub APIをリクエストする前にコミット対象となるファイル生成の処理を追加します。
まずはmodelのsqlファイルとtestのymlファイルのテンプレートを用意します。
↓modelのテンプレートです。
dbtで使っているJinjaに反応して意図したところで値が置き換わらなくなるので、一部エスケープしています。
やっぱり多少見づらくなるので他に良い方法はないだろうか・・・
{{ '{{' }}
config(
alias='{{ table_name }}',
)
{{ '}}' }}
{{ '{%' }} set column_lists = {{ column_list }} {{ '%}' }}
{{ '{{' }} production_logs_template('{{ table_name }}', column_lists) {{ '}}' }}
, result_record AS (
SELECT
{{ select_list }},
dre_transfer_at,
ROW_NUMBER() OVER (PARTITION BY {{ partition_column_list }}) AS row_number
FROM
records
), stg_record AS (
SELECT
{{ jst_converted_select_list }},
dre_transfer_at,
{{ '{{' }} jst_now() {{ '}}' }} AS dre_delivered_at,
FROM
result_record
WHERE
row_number = 1
)
SELECT
*,
{{ '{{' }} set_record_exported_at(column_lists) {{ '}}' }} AS dre__record_exported_at,
FROM
stg_record
↓testのテンプレートです。ログの一意性を担保するテストを追加します。
version: 2 models: - name: TABLE_NAME tests: - dbt_utils.unique_combination_of_columns: combination_of_columns: COLUMN_LISTS
次に以下のクラスを追加します。
BQから追加対象テーブルのカラム名を取得してgenerate_dbt_file_info関数に渡すことで、先ほど作成したテンプレートを元にファイルが生成されます。
import json import os import re import tempfile from typing import Any, Dict, List, Tuple from jinja2 import Environment, FileSystemLoader from ruamel.yaml import YAML class DBTModelFileGenerator: def _convert_column_with_at(self, column_name: str) -> str: return f"TIMESTAMP({column_name})" def _convert_column_with_id(self, column_name: str) -> str: return f"CAST({column_name} AS INT)" def _convert_utc_to_jst(self, column_name: str) -> str: return f"{{{{ timestamp_utc2datetime_jst('{column_name}') }}}}" def _generate_select_list(self, column_list: List[str]) -> str: converted_columns = [] for col in column_list: if col.endswith("_at"): converted_columns.append( f"{self._convert_column_with_at(col)} as {col}" ) elif re.search(r"(_id$|^id$)", col): converted_columns.append( f"{self._convert_column_with_id(col)} as {col}" ) else: converted_columns.append(col) return ",\n ".join(converted_columns) def _generate_jst_converted_select_list(self, column_list: List[str]) -> str: converted_list = [] for col in column_list: if col.endswith("_at"): converted_list.append(f"{self._convert_utc_to_jst(col)} as {col}") else: converted_list.append(col) return ",\n ".join(converted_list) def _generate_staging_sql(self, table_name: str, column_list: List[str]) -> str: select_list = self._generate_select_list(column_list) partition_column_list = ", ".join(column_list) jst_converted_select_list = self._generate_jst_converted_select_list( column_list ) # テンプレートのロード file_loader = FileSystemLoader("テンプレートファイルのパス") env = Environment(loader=file_loader) template = env.get_template("template_stg_production_logs.sql") # テンプレートのレンダリング sql = template.render( table_name=table_name, column_list=column_list, select_list=select_list, partition_column_list=partition_column_list, jst_converted_select_list=jst_converted_select_list, ) # tempdirにファイルを保存 output_path = os.path.join( tempfile.gettempdir(), f"{table_name}_stg_production_logs.sql" ) with open(output_path, "w") as tmp: tmp.write(sql) return output_path def _generate_staging_test(self, table_name: str, column_list: List[str]) -> str: yaml = YAML() yaml.indent(sequence=4, offset=2) with open( "テンプレートファイルのパス", "r", ) as template_file: template_content = yaml.load(template_file) template_content["models"][0]["name"] = f"{table_name}_stg_production_logs" test_definition = template_content["models"][0]["tests"][0] test_definition["dbt_utils.unique_combination_of_columns"][ "combination_of_columns" ] = column_list output_path = os.path.join( tempfile.gettempdir(), f"{table_name}_stg_production_logs.yml" ) with open(output_path, "w") as tmp: yaml.dump(template_content, tmp) return output_path def generate_dbt_file_info( self, new_table_and_column_names: List[Dict[str, Any]] ) -> List[Tuple[str, str, str]]: files = [] for record in new_table_and_column_names: table_name = record["table_name"] record_dict = json.loads(record["record"]) column_list = list(record_dict.keys()) sql_file_path = self._generate_staging_sql(table_name, column_list) test_file_path = self._generate_staging_test(table_name, column_list) files.append( ( f"追加先のdbt modelのパス/{table_name}_stg_production_logs.sql", sql_file_path, f"Add staging SQL for {table_name}", ) ) files.append( ( f"追加先のdbt testのパス/{table_name}_stg_production_logs.yml", test_file_path, f"Add staging test for {table_name}", ) ) return files
GitHubへのリクエスト処理追加
以下のクラスを追加し、create_pr関数に前段で生成したファイルの情報を渡すことでPRが生成されます。
認証にはAPIのリクエスト準備で発行したinstallation access tokenを使います。
import base64 import json import re from typing import Any, Dict, List, Tuple import jwt import requests from deleted_logs.adapter.output.github_app_token_manager import GitHubAppTokenManager class GitHubPRCreator: def __init__(self, session_start_time: str) -> None: self.OWNER = "XXX" self.REPO = "XXX" self.BASE_BRANCH_NAME = "main" numeric_only_session_start_time = re.sub(r"\D", "", session_start_time) self.NEW_BRANCH_NAME = f"feature/add_new_table_of_production_logs_to_staging_{numeric_only_session_start_time}" self.github_app_token_manager = GitHubAppTokenManager() def _is_branch_present(self) -> bool: headers = self.github_app_token_manager.generate_token_header() branch_url = f"https://api.github.com/repos/{self.OWNER}/{self.REPO}/git/ref/heads/{self.NEW_BRANCH_NAME}" response = requests.get(branch_url, headers=headers) if response.status_code == 200: return True elif response.status_code == 404: return False else: response.raise_for_status() return False def _create_branch(self) -> None: if self._is_branch_present(): return headers = self.github_app_token_manager.generate_token_header() # ベースブランチのSHAを取得 base_ref_url = f"https://api.github.com/repos/{self.OWNER}/{self.REPO}/git/ref/heads/{self.BASE_BRANCH_NAME}" response = requests.get(base_ref_url, headers=headers) response.raise_for_status() sha = response.json()["object"]["sha"] # ブランチ作成 branch_ref_url = ( f"https://api.github.com/repos/{self.OWNER}/{self.REPO}/git/refs" ) data = {"ref": f"refs/heads/{self.NEW_BRANCH_NAME}", "sha": sha} response = requests.post(branch_ref_url, headers=headers, json=data) response.raise_for_status() def _upload_file_to_repository( self, git_file_path: str, local_file_path: str, message: str ) -> None: headers = self.github_app_token_manager.generate_token_header() with open(local_file_path, "r") as file: content = file.read() encoded_content = base64.b64encode(content.encode()).decode() url = f"https://api.github.com/repos/{self.OWNER}/{self.REPO}/contents/{git_file_path}" # 同様のファイルが既に存在するか確認 response = requests.get(url, headers=headers) sha = None if response.status_code == 200: sha = response.json()["sha"] data = { "message": message, "content": encoded_content, "branch": self.NEW_BRANCH_NAME, } if sha: data["sha"] = sha response = requests.put(url, headers=headers, json=data) response.raise_for_status() def _push_files(self, files: List[Tuple[str, str, str]]) -> None: self._create_branch() for git_file_path, local_file_path, message in files: self._upload_file_to_repository(git_file_path, local_file_path, message) def _generate_pr_title(self, table_names: List[str]) -> str: return f"production_logs新規テーブル({','.join(table_names)})追加" def _generate_pr_body(self, table_and_column_names: List[Dict[str, Any]]) -> str: header = "このPRはdeleted_logsによって自動生成されたものです。\n\n以下のテーブルのステージング処理を追加しています:\n" lines = [] for record in table_and_column_names: table_name = record["table_name"] record_dict = json.loads(record["record"]) columns = ", ".join(record_dict.keys()) lines.append(f"**{table_name}**\nColumns: {columns}\n") return header + "\n".join(lines) def create_pr( self, table_names: List[str], column_names: List[Dict[str, Any]], files: List[Tuple[str, str, str]], ) -> str: self._push_files(files) headers = self.github_app_token_manager.generate_token_header() url = f"https://api.github.com/repos/{self.OWNER}/{self.REPO}/pulls" title = self._generate_pr_title(table_names) body = self._generate_pr_body(column_names) data = { "title": title, "body": body, "head": self.NEW_BRANCH_NAME, "base": self.BASE_BRANCH_NAME, } response = requests.post(url, headers=headers, json=data) response.raise_for_status() return response.json()["html_url"]
こんな感じのPRが生成されました。
※テストで作成したものなのでクローズしてます。

slackへの通知内容の修正
前段で生成したPRのURLを通知メッセージに追加します。
↓テストで飛ばした通知はこんな感じです。

ここで通知されたPRのレビューとマージを行うことで、Staging層のdbt modelが作られるようになりました。
まとめ
今回dbtのmodel生成を自動化したことで、2つの効果が得られました。
1つ目は、トイルの削減です。
これまで以下のフローで対応していましたが、
既存のdbt modelをコピペしてPR作成 → レビュー依頼 → マージ
自動化したことで、
PRを確認してマージ
だけででよくなりました。
元々大した工数はかかっていなかったものの、繰り返し発生する価値のない定型作業を減らすことができました。
そして2つ目は、Staging層へ新規ログテーブルが反映されるまでのラグ短縮です。
自動化したことで、他の対応でひっ迫している際に後回しにされることがなくなり、
これまではログ出力し始めてから分析可能になるまで最長7日かかっていたところ、導入後は大体1日以内で分析可能な状態になりました。
個人的には、タイミーにジョインするまでDevOps的なことがやれていなかったこともあり、運用は地味でつまらないイメージがあったのですが(すみません)、こうやって改善がまわせると運用も面白いなと最近思うようになりました。
We’re Hiring
DREグループではまだまだやっていきたいことがたくさんあるのですが、まだまだ手が足りておら
ず、ともに働くメンバーを募集しています!!
データに係る他のポジションやプロダクト開発などのポジションも絶賛募集中なのでこちらからご覧ください