はじめに
※Timee Product - Qiita Advent Calendar 2023 - Qiitaの12月8日分の記事です。
okodooooooonです
BigQueryの料金爆発。怖いですよね。
dbtでの開発が進んでたくさんのモデルを作るようになると、デイリーのビルドだけでも凄まじいお金が消えていったりします(僕はもう現職で数え切れないくらいやらかしてます)。
コストの対策として「パーティショニング」「クラスタリング」などが挙げられますが、今回は「増分更新」の観点で話せたらと思います。
「dbtのmaterialized=’incremental’って増分更新できておしゃれでかっこよくてコストもなんとなく軽くなりそう!」くらいの認識でさまざまな失敗を経てきた僕が、BigQueryにおけるincrementalの挙動を説明した上で、タイミーデータ基盤における増分更新の使い方についてまとめたいと思います。
※この記事はdbt + BigQueryの構成に限定した内容となります。BigQuery以外のデータウェアハウス環境では今回紹介する2つ以外のincremental_strategyが用いられるので、そちらご注意ください!
BigQueryの増分更新の挙動についておさらい
dbtはincremental処理において、BigQuery向けに merge と insert_overwrite という2つのincremental_strategy(増分更新のやり方のオプション)を提供しています。
名前だけ見てもちんぷんかんぷんなのでそれぞれ解説していこうと思います。
MERGE戦略
MERGEはBigQueryにおけるデフォルトのincremental方針となります。
dbtのconfigブロックの定義は以下のようになります。
{{ config( materialized='incremental' , unique_key='xx_key' ) }}
incremental_strategy = mergeの時に実際にBigQueryに発行されるMERGE文はこんな感じになります。
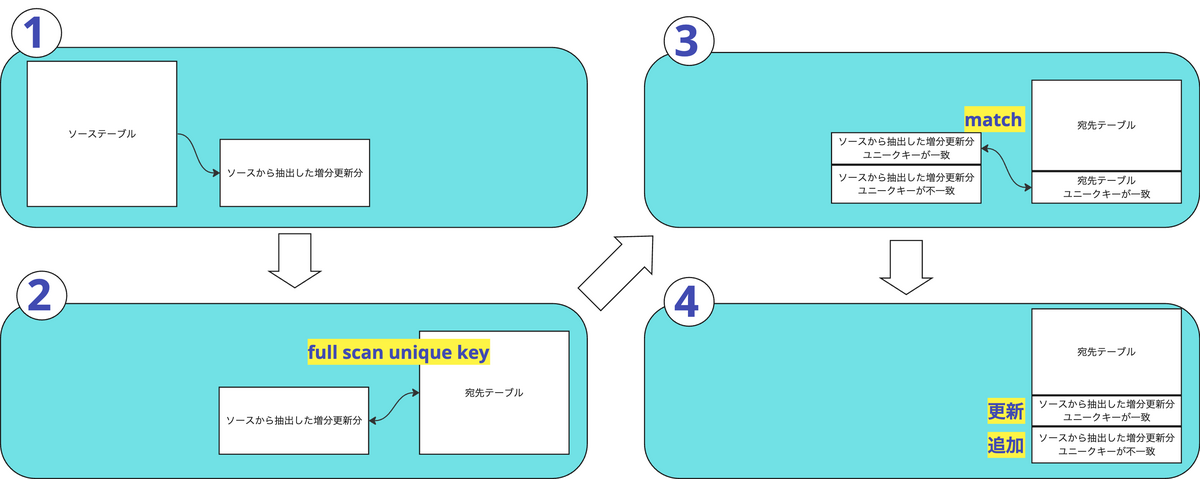
merge into `xxxx_project`.`xxx_dataset`.`atesaki_table` as DBT_INTERNAL_DEST using ( {{model_sql}} ) as DBT_INTERNAL_SOURCE on ( DBT_INTERNAL_SOURCE.ユニークキー1 = DBT_INTERNAL_DEST.ユニークキー1 AND DBT_INTERNAL_SOURCE.ユニークキー2 = DBT_INTERNAL_DEST.ユニークキー2 ... ... ) -- ユニーク指定キーがマッチングした場合 when matched then update set ソース側の行でマッチングした宛先テーブルの行を上書き -- 宛先テーブルにユニーク指定キーが存在しなかった場合 when not matched then insert ソース側の行を追加
この際のON句の中身が問題で
on ( DBT_INTERNAL_SOURCE.ユニーク指定キー1 = DBT_INTERNAL_DEST.ユニーク指定キー1 AND DBT_INTERNAL_SOURCE.ユニーク指定キー2 = DBT_INTERNAL_DEST.ユニーク指定キー2 ... )
といった式になっているので、宛先テーブルの全件を走査して、マッチする列がないかを確認しています。宛先テーブルが巨大になればなるほど、クエリコストが問題となってきます。
概念図で示すとこんな感じ
INSERT+OVERWRITE戦略
dbtのconfigブロックは以下のようになります。
{{config( materialized='incremental', incremental_strategy='insert_overwrite', partitions=var('last_31_days'), # dbt_project.ymlで定義した日付のリストが格納された変数 partition_by={ 'field':'xx_datetime', 'data_type': 'datetime', 'granularity': 'day' } )}}
発行されるMERGE文は以下のような形。参考:https://docs.getdbt.com/reference/resource-configs/bigquery-configs#the-insert_overwrite-strategy
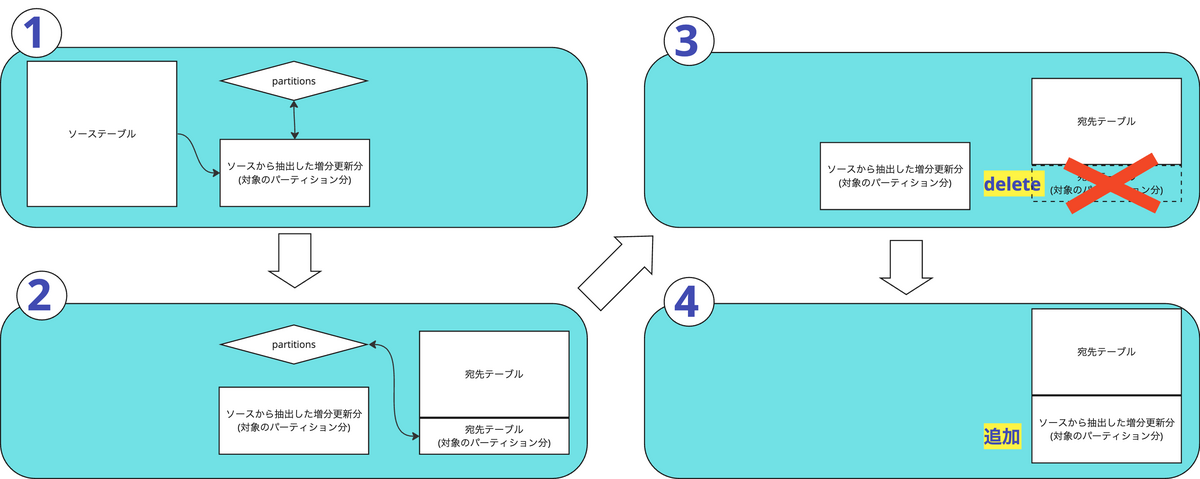
create temporary table {{ model_name }}__dbt_tmp as ( {{ model_sql }} ); declare dbt_partitions_for_replacement array<date>; -- ソーステーブルから上書きすべき日付の配列をdbt_partitions_for_replacementにセット set (dbt_partitions_for_replacement) = ( select as struct array_agg(distinct date(max_tstamp)) from {{ model_name }}__dbt_tmp ); merge into {{ destination_table }} AS DEST using {{ model_name }}__dbt_tmp AS SRC on FALSE -- on Falseにすることでキー同士のマッチングは発生しない -- 宛先テーブルの該当パーティションを削除する。参考:https://cloud.google.com/bigquery/docs/using-dml-with-partitioned-tables?hl=ja#using_a_filter_in_the_search_condition_of_a_when_clause when not matched by source and {{ partition_column }} in unnest(dbt_partitions_for_replacement) then delete -- ↑で削除した後にソースをinsertする when not matched then insert ...
指定したパーティションを削除した後に、ソーステーブルをinsertするような処理をしています。
ソースにも宛先にもfull scanが走らないので、クエリコストとしては軽くなります
概念図で示すとこんな感じ
増分更新ロジックの使い分けについて
上記のロジックを理解した上で増分更新についてまとめると以下のようになります。
- incremental_strategy=mergeのユースケース
- ソーステーブルが巨大で宛先テーブルが小さい場合の増分更新
- ソーステーブルにフルスキャンを走らせることなくコストを抑えた状態で、ユニークを保って増分更新ができます
- ソーステーブルが巨大で宛先テーブルが小さい場合の増分更新
- incremental_strategy=insert_overwriteのユースケース
- 宛先テーブルが巨大な場合の増分更新
- ソーステーブル, 宛先テーブルともにフルスキャンを走らせることなくコストを抑えた状態で増分更新できます
- 宛先テーブルが巨大な場合の増分更新
insert_overwriteの注意点
insert_overwriteではdbt_project.ymlにて以下のように静的なリストとしてパーティション指定のリスト変数を作成した後に
last_2_days : [ current_date('Asia/Tokyo') , date_sub(current_date('Asia/Tokyo'), interval 1 day) ]
以下のように
{{config(
materialized='incremental',
incremental_strategy='insert_overwrite',
partitions=var('last_2_days'),
partitionsに渡す必要があります
上の直近2日間のpartitions指定だと、もし何かしらの要因でJobが3日間転んだりしていたら、3日目に復旧したとしても
障害1日目:レコード無。障害2日目:レコード有。障害3日目:レコード有
といった形の歯抜けテーブルになってしまいます。障害を踏まえたバッファ分を余裕を持って指定しておくことが大切です。
insert_overwriteはパーティションをごっそり入れ替えるようなロジックであるため、ユニークがこのロジックだけでは担保されません。これによって生じる想定される不具合を見てみましょう。
例えば「ユーザーごとの月毎と日毎の両方のステータスを保持するようなテーブル」を想定してみます。
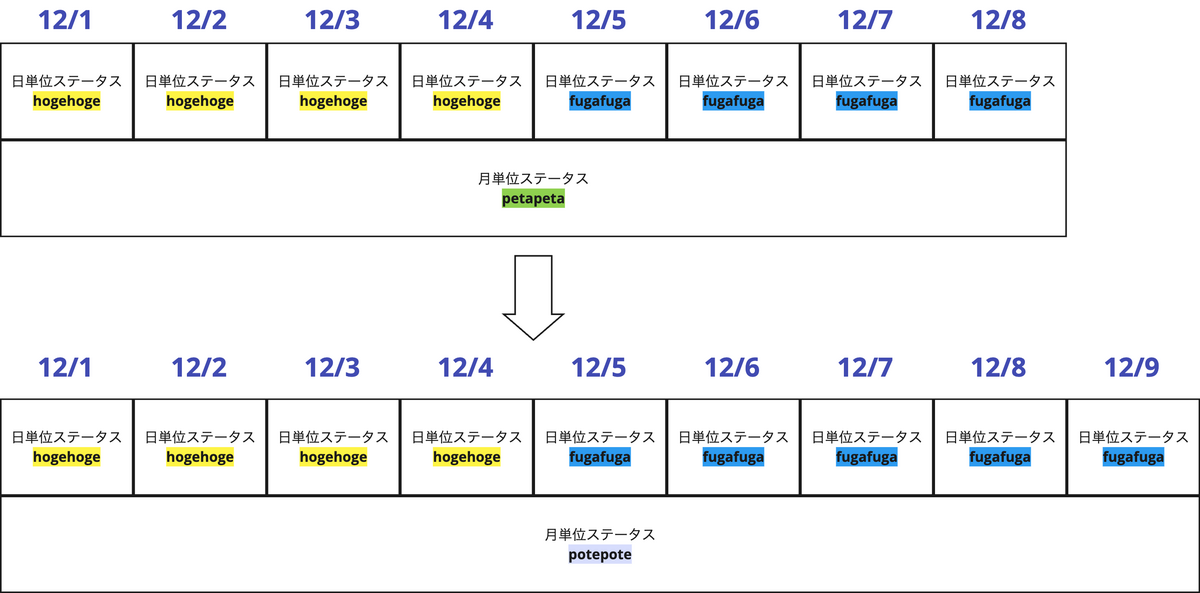
月単位のステータスが12/9で petapeta ⇒ potepoteに変更されたとします。
この時に直近1週間をpartitionsに指定するinsert_overwriteで増分更新をすると仮定すると12/9の更新で以下のようになります。
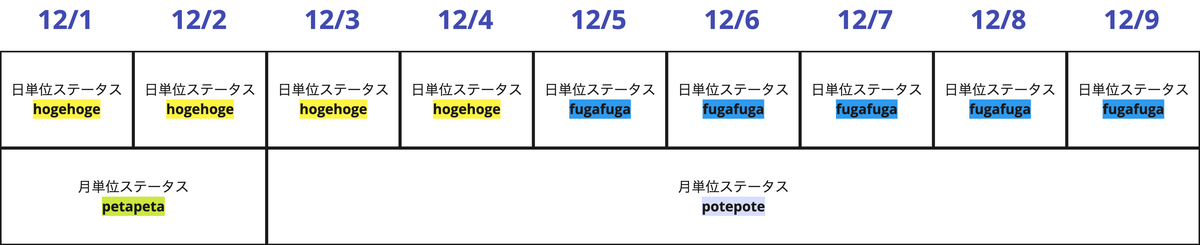
このように直近1週間のパーティションをそのまま置き換えただけなので、12/1, 12/2の月単位のステータスがpetapetaのままになってしまい、同じ月に2つの月単位ステータスを持つ形になってしまいます。このようなケースを防ぐには、partitionsに「直近1ヶ月分の日付のリスト」を渡してあげる必要があります。
過去の値が変わりうるテーブル(月末の締め処理で金額が変動しうる会計処理とか?)に対してinsert_overwriteを適用するには、「どの期間をpartitionsに渡せば安全なのか」を考えることがとても重要になります!
タイミーの増分更新の対象について
挙動を正確に理解できたところでタイミーデータ基盤における増分更新のユースケースを見ていきましょう!
- mergeを使用して増分更新しているケース
- firebaseなどのログテーブルから一部種別のログだけを抽出するようなテーブル
- 巨大なソーステーブルから集約した値を蓄積するようなテーブル
- insert_overwriteを使用して増分更新しているケース
- 宛先がソースと比較して膨大になるsnapshot factテーブル
- その他ログテーブルなどから作られる巨大なfactテーブル
こんな形で当社では現状は使い分けています。 実装難度がinsert_overwriteの方が高いので、mergeで済むケースはmergeにしちゃってます。
おわりに
BigQueryにおけるincrementalの挙動と、それぞれのメリデメ、なぜコストが下がるのかあたりを解説しました。
incrementalに関する公式Docを見てもなんとなく言ってることわかりそうでわからない。
MERGE文などを通して公式Docなどで紹介されているが、普段SELECT文を書くことが主となってしまって、DMLにあたるMERGE文は読みづらいしわかりづらい。などといった方々の参考になれたら嬉しいです。
We’re Hiring
タイミーのデータ統括部はやることがまだまだいっぱいで仲間を募集しています!興味のある募集があればこちらから是非是非ご応募ください。