はじめに
こんにちはokodoonです
タイミーのデータ基盤に対してデータモデリングを始めてしばらく経ったので、現状の全体構成を紹介したいと思います
全体構成
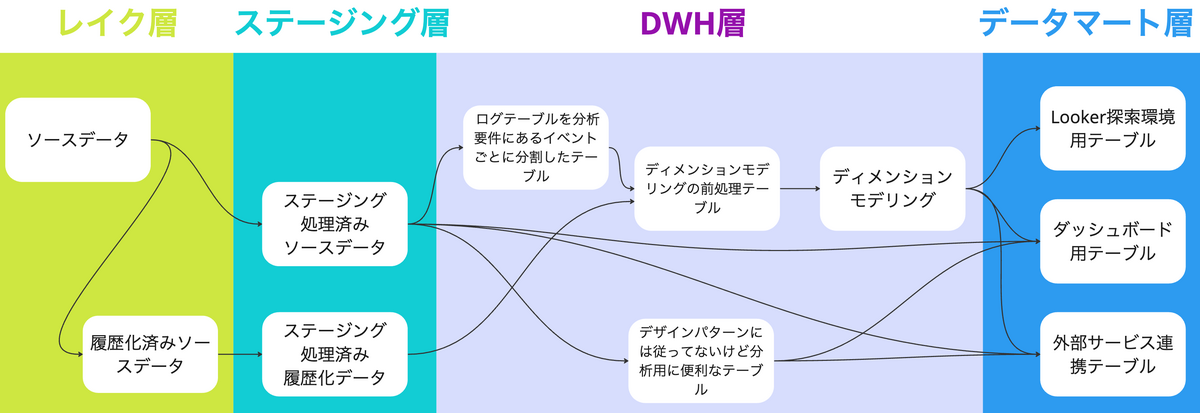
弊社のBigQueryは以下の4層にレイヤリングされています
それぞれの役割は以下のような切り分けになっています
| レイヤー名 | 役割 |
|---|---|
| データレイク層 | 複数ソースシステムのデータを未加工の状態でBigQueryにロードする宛先 dbt snapshotによるソースの履歴化 |
| ステージング層 | 複数ソースシステムのデータを共通した処理でクレンジングする層 |
| DWH層 | ソースシステムのデータ形式を分析に適した形に変換する層 ディメンショナルモデリング/ログテーブルをイベント単位に分割/その他便利テーブル作成 |
| データマート層 | 特定用途に対して1:1で作成されたテーブル群を格納する層 ダッシュボード用テーブル/Looker用テーブル/GoogleSheets用テーブル/外部サービス連携用テーブル |
図で表すとこんな感じです
DWH層, データマート層の切り分けについて
「DWHとデータマートとは?どう切り分けるか?」と100人に聞いたら100通りの答えが返ってきそうなこちらの定義
弊社内ではデータ基盤チーム内で議論した結果、以下のような切り分けをしています
- DWH: ステージングデータを分析ニーズに合わせて加工したもの - データマート: 特定ニーズに対して1:1で作成されたテーブル
なので
- ディメンショナルモデリングなどの分析用データへ変換したテーブル
- クエリを発行する際に、結果の出力が重くなってしまうテーブルを軽量化したもの
などがDWH層に格納されているテーブル群で
- 特定ダッシュボード用に作られたテーブル
- Looker探索環境用に作られたwide_table
- 外部サービス連携用に成形されたテーブル
などが現在データマート層に格納されているテーブル群になります
※「ダッシュボードに1:1で対応するマートを作る方針なのかあ」と思われるかもですが、こちらは現在推進中のdbt exposureを用いたアウトプット管理を見据えているためです(またこの辺りは別の機会にアウトプットします!)
各層の説明を少しだけ深掘り
データレイク層
この層でdbt snapshotを活用した履歴化を実行しています
下流のステージング層/DWH層などで履歴化をしていない理由としては、何かしらの加工がされたあとのデータを履歴化する場合、加工処理に何かしらのバグや想定漏れがあった場合のロールバックが大変なためです
分析に使用する場合は以降の層でクレンジング/モデリングされたデータのみでいいため、基本的に分析ユーザーはデータレイク層へのアクセス権限を保持していません
ステージング層
以下のような処理を加えて、生データをクレンジングしています
- データ型の変更と統一
- パーティショニング/クラスタリング
- データマスキング
- 品質担保のテスト
- uniqueテスト
- Nullテスト
- 外部キーテスト
ユーザーが3NF形式のデータに対してクエリを書く場合は、品質が保証されたステージング層のテーブルに対してクエリを実行してもらうような運用にしています
DWH層
DWH層内は以下のような区分が作られています
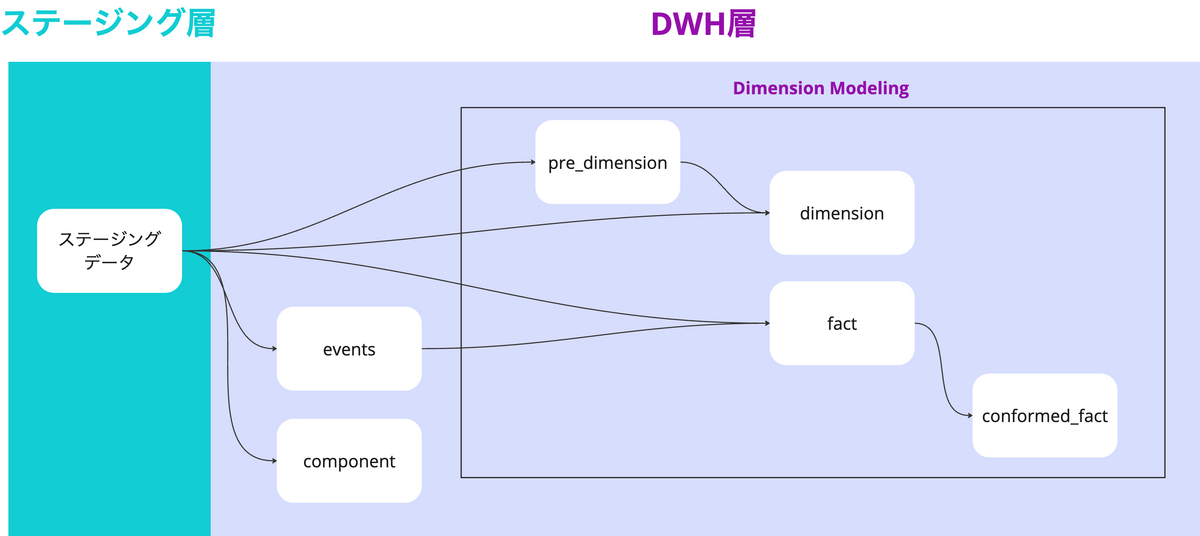
| DWH層内区分 | 役割 | dbtのフォルダパス |
|---|---|---|
| events | ログテーブルを分析要件にあるイベントごとに分割整理して軽くしたテーブル群 | models/dwh/events |
| component | ディメンショナルモデリングのデザインパターンに当てはまらないが便利な部品のようなテーブル群 | models/dwh/component |
| pre_dimension | 同一属性単位にドメイン情報を結合 ドメイン要件に従ったフラグ生成などの複雑な事前処理 |
models/dwh/dimension_modeling/pre_dimension |
| dimension | SCD Type2カラムの生成(https://en.wikipedia.org/wiki/Slowly_changing_dimension#Type_2:_add_new_row) サロゲートキーの生成 |
models/dwh/dimension_modeling/dimension |
| fact | ビジネス指標の作成 関連Dimensionのサロゲートキーの反映 |
models/dwh/dimension_modeling/fact |
| conformed_fact | 複数プロセスを跨いだよく使われるfactの組み合わせをconformed dimensionで結合 複数プロセスを跨いだビジネス指標の作成 |
models/dwh/dimension_modeling/conformed_fact |
弊社Dimensional Modelingについて
弊社Dimensional Modelingについてざっくり解説します
- SCD Type 6の採用
- dimensionテーブルは「履歴化されたテーブル(Type2)」と「最新情報を持つテーブル(Type1)」に分けることなく、SCD Type1~3の全てを一つのテーブルで管理する方針としています
- こうすることでFactに登録するサロゲートキーが少なくなり、分析時のクエリと思考がスリムになると考えています
- dimensionテーブルは「履歴化されたテーブル(Type2)」と「最新情報を持つテーブル(Type1)」に分けることなく、SCD Type1~3の全てを一つのテーブルで管理する方針としています
- 採用しているFactテーブルのパターン
- Transaction Fact + Factless Factを接合したFactテーブル
- Transaction FactテーブルとFactless Factテーブルを別々に作るのではなく、ビジネスプロセス単位でまとめてくっつけています
- 例えば「買い物プロセス」を仮定した場合に、Transaction Factにあたる
合計売上とFactless Factにあたる決済回数が同一の買い物Factテーブルにあるイメージです
- 例えば「買い物プロセス」を仮定した場合に、Transaction Factにあたる
- Transaction FactテーブルとFactless Factテーブルを別々に作るのではなく、ビジネスプロセス単位でまとめてくっつけています
- Snapshot Factテーブル
- Transaction FactやFactless Factではうまく表現できないような指標(etc. ユーザー数全体の推移, 銀行残高の推移, )を日,月単位の粒度でスナップショットして保持します
- 例えば日毎のユーザーdimensionのサロゲートキーを保持するようなSnapshot Factテーブルを作成することで、日単位のユーザー数の推移をDimensionテーブルで絞り込み可能な状態で追えるようになります
- Transaction Fact + Factless Factを接合したFactテーブル
- FatなFactテーブル
- Factテーブルは分析ニーズのあるビジネスプロセス単位で作られると思いますが、そのビジネスプロセスで発生する指標を全て一つのFactテーブルで完結して出力できるような方針をとっています
- 買い物の決済プロセスのFactテーブルを仮定すると、
決済Factの決済金額*決済Dimensionの消費税率=消費税金額みたいにFactとDimensionを組み合わせて新しい指標を出力するのではなく、決済Factテーブルに決済金額,消費税金額を二つとも持っておくような形です
- 買い物の決済プロセスのFactテーブルを仮定すると、
- こうすることで「Factテーブルに定義されている指標をDimensionテーブルで絞り込むだけでいい」「Factテーブルにない指標があればFactテーブルに足せばいい」とクエリ作成時の思考が軽くなると考えています
- Factテーブル上に社内の指標を全て整理して保持している状態です
- Factテーブルは分析ニーズのあるビジネスプロセス単位で作られると思いますが、そのビジネスプロセスで発生する指標を全て一つのFactテーブルで完結して出力できるような方針をとっています
データマート層
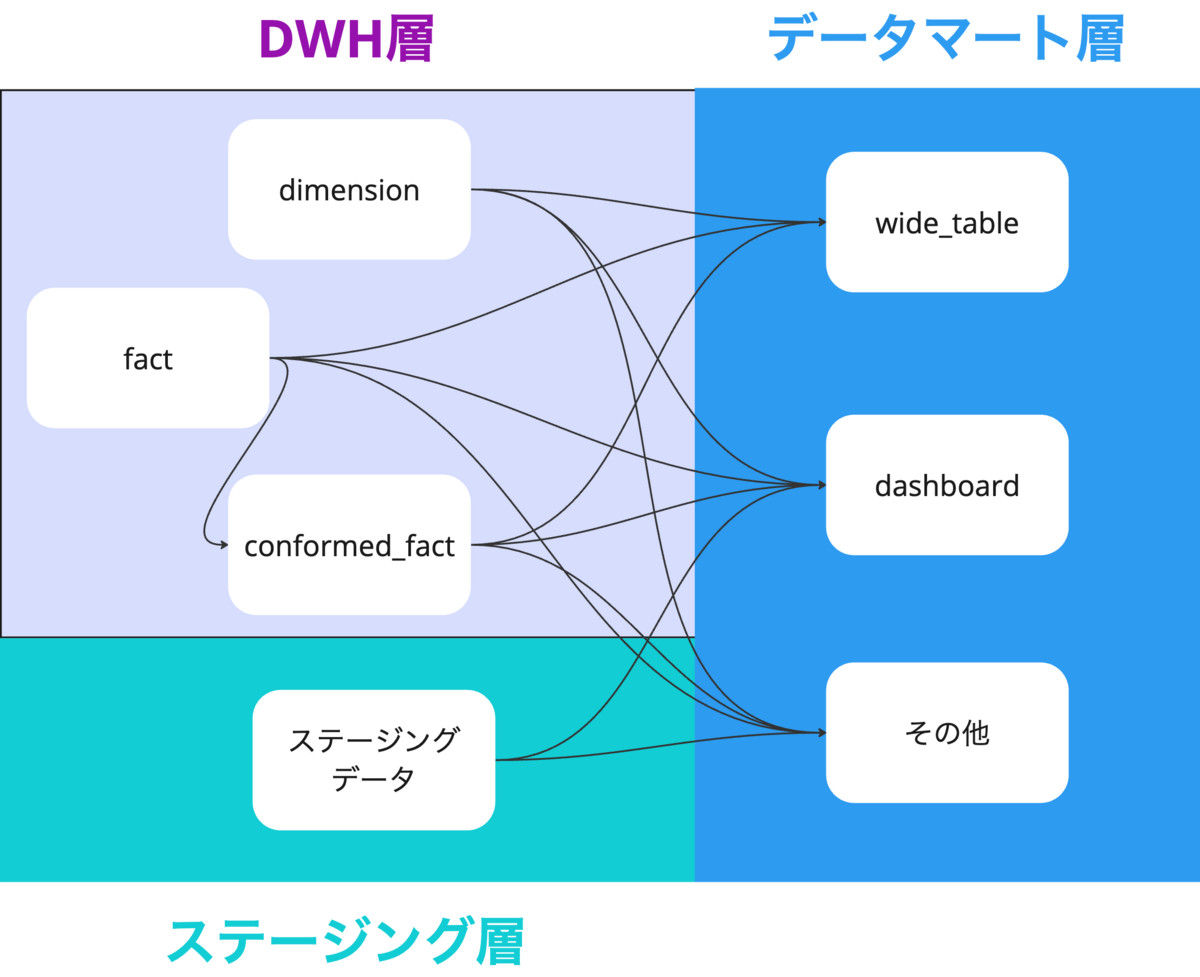
| データマート層内区分 | 役割 | dbtのフォルダパス |
|---|---|---|
| wide_table | ディメンショナルモデリング済みテーブルをJOIN済みの状態にしたテーブル群 Lookerの探索環境に1:1で対応している |
models/marts/wide_table |
| dashboard | LookerStudioダッシュボード, Spreadsheetのコネクテッドシートに1:1で対応しているテーブル群 | models/marts/dashboard |
| その他 | 他サービスに連携していたり、特定プロジェクトのために一時的に作られるテーブル群 | models/marts/{{その他}} |
Lookerとの接続について
LookerのUIを見てみると、dimensionとmeasureが選択できるような、ディメンショナルモデリングを意識したものになっています
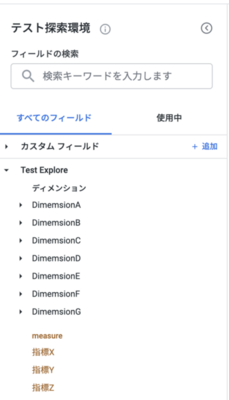
そこで弊社ではこの画像のようにLookerのデザインに乗っかる形で、Lookerの接続先をディメンショナルモデリング済みのwide_tableとしており、スター内のFactテーブルの指標をmeasureとして、Factに接続するDimensionテーブル内の要素をDimensionテーブルごとに分割して表示しています
こうすることで
商品の生産国が中国の決済金額を決済方法ごとに出力したい
というユーザーの思考があった時に
商品の生産国だから => 商品Dimensionの生産国を選択 決済方法だから => 決済Dimensionの決済方法を選択 出力したい指標は決済金額だから => Factの決済金額を選択
とLooker上のユーザーの行動に繋がると思っており、
ユーザーの思考,実際に走るクエリ ,Lookerの探索環境のUI ができるだけ一致するようなデザインになっています
こうすることでLookerへのフィードバックがモデリングをより便利にすることに繋がり
モデリングへのフィードバックがLookerをより便利にすることに繋がります
ダッシュボード用 / スプレッドシート用のデータマートについて
基本的にマートはView形式で作成します (補足:Viewテーブルとは)
Viewとして作成することで無駄なビルドやコスト増加を避ける方針です
マート化する判断基準は「正確性と安全性を保守すべき対象かどうか」であり、チーム内で定めた基準に従ってマート化を実施してアウトプットをコード管理します
ダッシュボード用 / スプレッドシート用のデータマートをdbtで作成するのでdbt上でリネージュ管理が行えるようになり、破壊的な変更が上流で発生した場合に保守対象のダッシュボードへの影響を抑えることができます
作成したマートに対応するdbt exposureを宣言することでデータオーナー管理やアウトプット先管理も行えるようにする予定です
将来構想
数ヶ月以内に実現したい将来
- dbt exposureによるオーナーを含めたアウトプットの管理
- 主要ビジネスプロセスの全モデル化
1年以内とかにはやりたい将来
- サンドボックス層の作成
- ポリシータグを用いた、メンバーのアクセス可能情報レベルに応じたクエリ範囲の制限
まとめ・今後の課題
弊社は組織拡大のスピードがとても早く、データ活用者数もとても多いので
クエリ作成者間で出力される指標値がブレる。ダッシュボードやLookerの値とアドホッククエリの値がブレる。そもそも定義がブレている
などの問題を防ぎつつ
簡便にあらゆる指標値がクエリできる
ように、ディメンショナルモデリングを主軸としたデータモデリングを推進してきました
現在は作成したモデル数はかなりのものになり、それに従ってLooker環境もリッチになってきたのですが、アナリストが作るアドホッククエリやダッシュボード作成クエリにまだまだ採用してもらえていない課題感があります
モデリング済みテーブルを使ってクエリを書くのはDWH開発に参加してくれているアナリストメンバーに集中していて、他アナリストメンバーにモデリングなどの技術的内容とDWHの開発内容などをうまく同期できていない状態です
モデリング済みテーブルを使用することで
- 指標が全社定義と常に一致する
- Dimensionの履歴を考慮した指標出力が可能になる
- クエリ文量が1/5とかになる
- クエリパフォーマンスが向上するケースもある
などメリットも大きいと思うので、モデリング手法の理解を助けるアウトプットやワークショップなど様々なHowを通して、アドホックなクエリに採用してもらってもっとフィードバックのサイクルが高速化するようにしていきたいです!
We’re Hiring
タイミーのデータ統括部では、ともに働くメンバーを募集しています!!