こんにちは!タイミーでデータアナリストをしているkantaと申します。
普段はマーケティングの皆様とCM施策やCRM関連の分析を担当したり、他部署向けの講習会を企画したりしております。11月から半年ほど育休を取得予定のため、育休前最後の仕事(?)として当ブログの執筆を担当いたします。
さて、今回は「BigQuery + Looker Studioでt検定した話」と題しまして、その方法をご紹介できればと思います。
- なぜ BigQuery + Looker Studioでt検定をしたいのか?
- BigQuery + Looker Studio でt検定する手順
- BigQuery + Looker Studioでt検定した感想
- We’re Hiring!
なぜ BigQuery + Looker Studioでt検定をしたいのか?
タイミーでは、BIツールとしてLooker Studioを使っていますが、分析の中でいくつか機能の不足を感じる点があります。その一つが、今回のタイトルにもなっているt検定です。t検定はその施策の効果が有意であったか、有意でなかったかを推定するために非常に重要な要素です。PythonやRなどのプログラミング言語だけでなく、Excel、スプレッドシートおよびLookerでも実施できます。
しかしながら、Looker Studioではt検定がサポートされておらず、他のツールで出力した検定結果をインポートする必要があります。(2024年10月現在)
そうなると、一つの検定を実施するために以下の三つを管理しなければなりません。

これらの管理工数を少しでも削減するために、以下のような構成でLooker Studio上にt検定結果を表示したいと思います。

BigQuery + Looker Studio でt検定する手順
それでは、その手順についてご紹介します。
UDFの実装につきましては、以下のブログを参考にさせていただきました。
BigQueryで始めるt検定 - Re:ゼロから始めるML生活
1. UDFの作成
BigQueryにはユーザー定義関数(UDF)という機能があり、SQLまたはJavaScriptで関数を作成できます。この機能を利用して、JavaScriptでt検定のUDFを作成します。
1-1. JavaScriptライブラリ「jStat」のダウンロード
GitHubリポジトリからjstat.jsをダウンロードします。
https://github.com/jstat/jstat/blob/1.9.6/dist/jstat.js

1-2. 任意のGCSバケットにjstat.jsをアップロード
GCSバケットにアップロードし、バケット名とファイルパスを控えてください。
ここでは、YOUR_BUCKET 配下にlibraries/jstat.js として作成したものを記載します。
1-3. p値を算出するUDFの作成
以下のクエリをBigQueryで実行します。
YOUR_PROJECT・YOUR_DATASETは事前に作成しておいてください。
CREATE OR REPLACE FUNCTION `YOUR_PROJECT.YOUR_DATASET.studentt_cdf`(t FLOAT64, dof FLOAT64) RETURNS FLOAT64 LANGUAGE js OPTIONS ( library="gs://YOUR_BUCKET/libraries/jstat.js" ) AS """ // スチューデントのT分布を用いて、与えられたt統計量と自由度に対する双方向のp値を計算 return jStat.studentt.cdf(-Math.abs(t), dof) *2 """
1-4. t検定を実施するUDFの作成
1-3で作成したUDFを利用し、t検定を実施するUDFも作成します。
同様に以下のクエリを実行してください。
CREATE OR REPLACE FUNCTION `YOUR_PROJECT.YOUR_DATASET.ttest_ind`(data ARRAY<FLOAT64>, data2 ARRAY<FLOAT64>) AS (( WITH dataset1 AS ( SELECT d AS A FROM UNNEST(data) as d ) ,dataset2 AS ( SELECT d AS B FROM UNNEST(data2) as d ) , mean AS ( SELECT AVG(A) AS ma, AVG(B) AS mb FROM dataset1, dataset2 ) , lena AS ( SELECT COUNT(A) AS len_a FROM dataset1 ) , lenb AS ( SELECT COUNT(B) AS len_b FROM dataset2 ) , Ama AS ( SELECT A, ma, A - ma AS A_ma, FROM dataset1, mean ) , bmb AS ( SELECT B, mb, B - mb AS B_mb, FROM dataset2, mean ) , pow_Ama AS ( SELECT SUM(A_ma * A_ma) AS A_ma_2 FROM Ama ) , pow_Bmb AS ( SELECT SUM(B_mb * B_mb) AS B_mb_2 FROM bmb ) , S2 AS ( SELECT (A_ma_2 + B_mb_2) / (len_a + len_b - 2) AS s_2 FROM pow_Ama, pow_Bmb, lena, lenb ) , t AS ( SELECT len_a, len_b, (ma - mb) / SQRT((s_2/len_a) + (s_2/len_b)) AS t_value FROM mean, S2, lena, lenb ) SELECT `YOUR_PROJECT.YOUR_DATASET.studentt_cdf`(t_value, len_a + len_b-2) AS p_value FROM t ))
2. クエリの作成
以下のクエリを実行し、p値を得ることができます。
実際に使用するときは各グループの数値をARRAY_AGG で配列にして扱うことが多いです。
WITH test_data AS ( SELECT [0.0,5.0,29.0,3.0,4.0,32.5,46.3] AS A, [9.0,4.0,5.0,6.0,4.0,2.0,3.0,1.0,2.0,4.0] AS B ) SELECT `YOUR_PROJECT.YOUR_DATASET.ttest_ind`(A, B) AS p_value FROM test_data

3. Looker Studioで可視化
3-1. Looker StudioのデータソースでBigQueryを選択
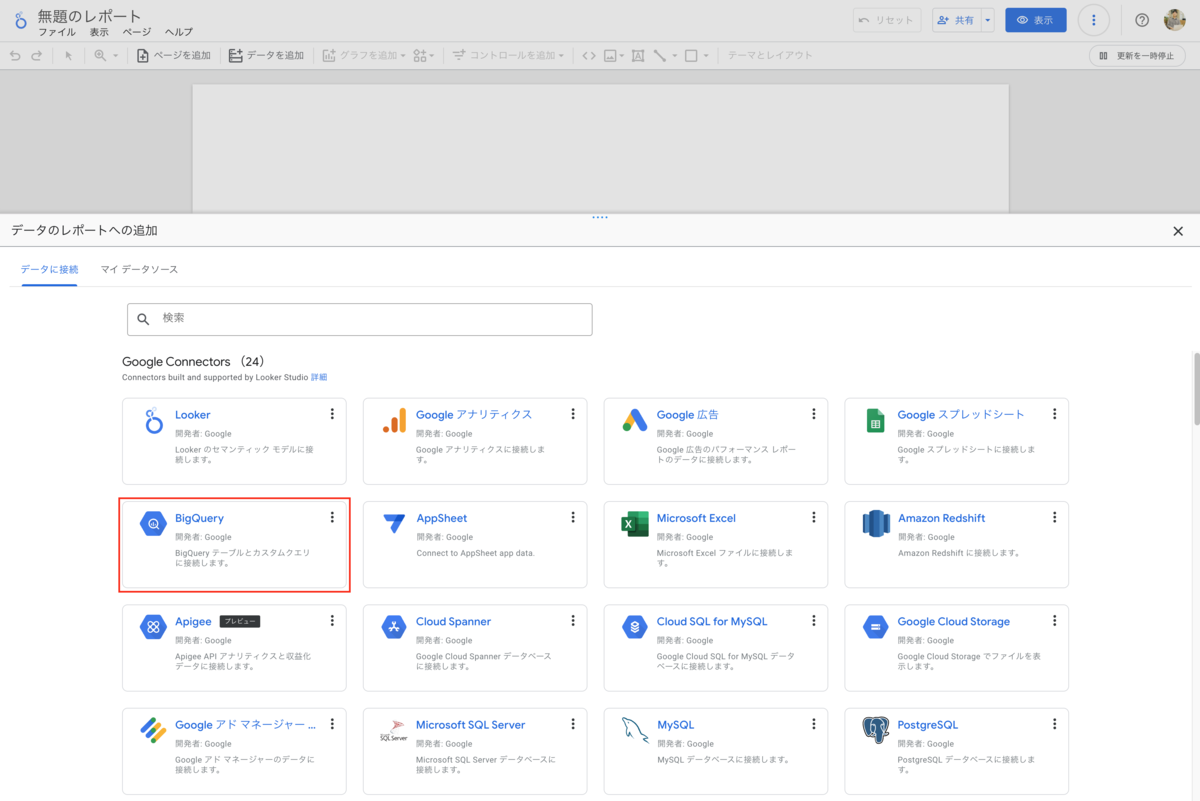
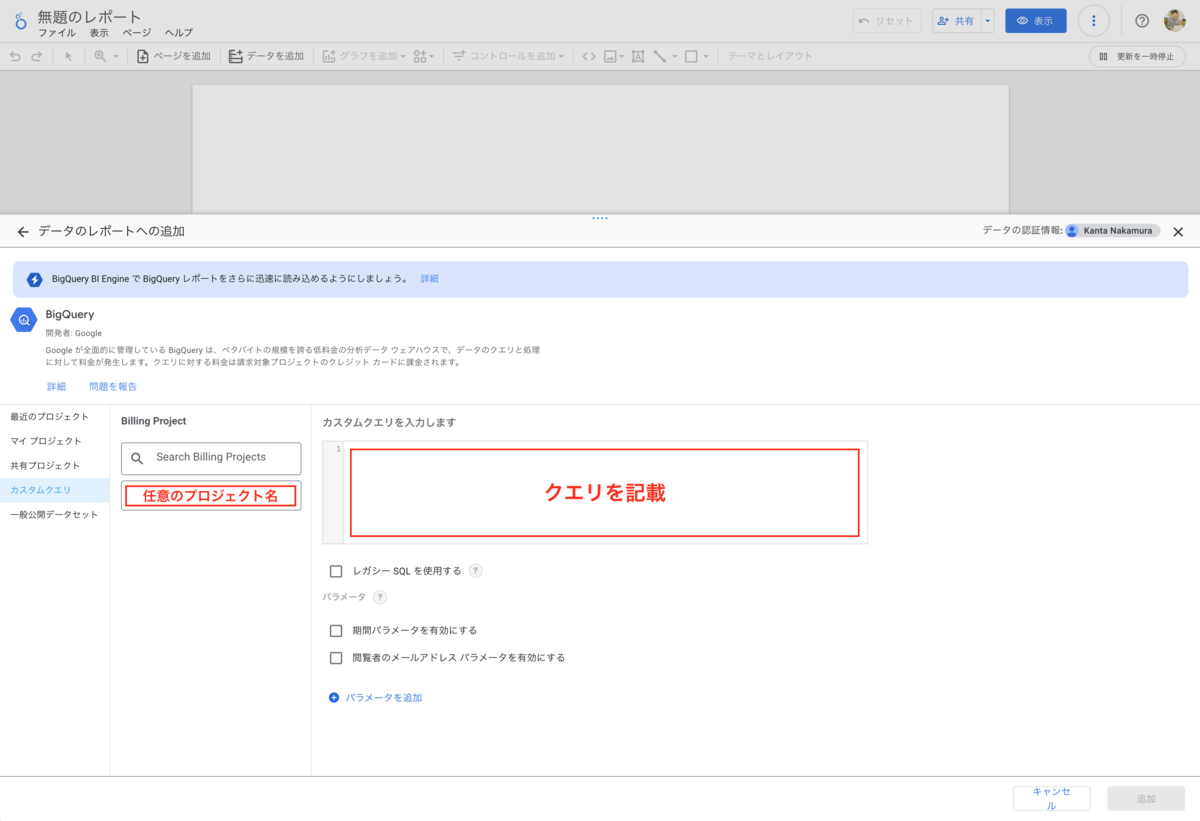
3-2. 先ほど作成したカスタムクエリを記述
定義したUDFはLooker Studioからも実行できます。
3-3. 見た目を整えて完成!
詳細は公式ドキュメントをご確認ください。
手順は以上となります。

BigQuery + Looker Studioでt検定した感想
ここまでお付き合いいただきありがとうございました。今回の最大のメリットは、すでに述べたように、管理すべきツールを減らせる点にあります。
その一方で、実際のデータだとクエリが冗長になり、レビューやメンテナンスがしづらくなってしまう場合もあります。
また、そもそも検定とBIツールによる可視化は分けて行うべきという考え方もあると思い、実装してみたものの用途は限られるという印象です。
あくまで選択肢の一つとして、分析の要件や環境に合わせた選択が必要ですね。
We’re Hiring!
私たちは、ともに働くメンバーを募集しています!!
カジュアル面談も行っていますので、少しでも興味がありましたら、気軽にご連絡ください。