この記事はTimee Product Advent Calendar 2025 21日目の記事です。
データエンジニアリング部DSグループ所属の藤井と申します。現在タイミーで推薦エンジンの改善に取り組んでいます!
この記事では、タイミーの推薦エンジンにおける候補生成で導入している ANN(Approximate Nearest Neighbor)と、その ANN用ベクトルを作る Two-Tower モデルを題材にします。そして、このドメインで重要なテーマのひとつである Negative Sampling、特に In-Batch Negative Sampling を使ったモデル開発における課題と対策について議論していきます。
ANNはRAG(Retrieval-Augmented Generation)のバックエンドにおいても使用されることが多いので、ぜひ読んでいただけると嬉しいです!
Two Towerモデル利用の背景
ここからは Two-Tower モデルの話に入っていきます。
推薦エンジンで推薦を行う際、推薦対象となる item v をすべての user u に対して brute force で厳密に計算すると、組合せ爆発により計算量が
となってしまいます。そのため、件数が増えるにつれて、現実的なコストでは計算することが難しくなっていきます。
例として、日本の大学生300万人に対し、100万冊の本からベストな本を推薦する状況を考えましょう。この場合、「300万人×100万冊」で3兆通りもの組み合わせが生じてしまいます。推薦エンジンでの重たい計算や、LLM への API コールが必要なケースでは、このように全件をそのまま計算すると、非現実的なコストがかかる可能性が高いです。
ここで挙げた例のように、item数とuser数の組み合わせが多くなるケースでは、何らかの方法でうまく候補を抽出し、計算量を削減する必要があります。
この計算量の問題に対処するため、タイミーではANNおよびANNに使う推薦用のベクトル(埋め込み)を生成するために Two-Tower モデルを利用しています。
Two-Tower モデルと InfoNCE Loss のおさらい
Two-Tower モデルでは、損失関数として InfoNCE Loss がよく使われます。
以下の InfoNCE Loss の式は、In-Batch Negative Sampling(「同じミニバッチ内の他アイテムをネガティブとして扱う」設定)を仮定した形になっています。
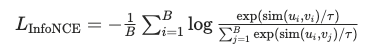
ここで、
: バッチ内 i 番目のユーザのベクトル
: そのユーザに対する正例(ポジティブ)アイテムのベクトル
: バッチ内に含まれる任意のアイテムのベクトル
: コサイン類似度などの類似度関数
: 温度パラメータ
: バッチサイズ
分子は「ユーザ と、そのユーザに対する正例アイテム
との類似度」を、
分母は「同じバッチ内に存在するすべてのアイテム との類似度の総和」を表しています。
この式から分かるように、どのサンプルをネガティブとして扱うか は InfoNCE の性能に直結する重要な設計要素であり、これまでに多くの研究が行われています。
本記事では、このうち Two-Tower モデル × In-Batch Negative Sampling という設定にフォーカスして話を進めます。
In-Batch Negative Sampling とは
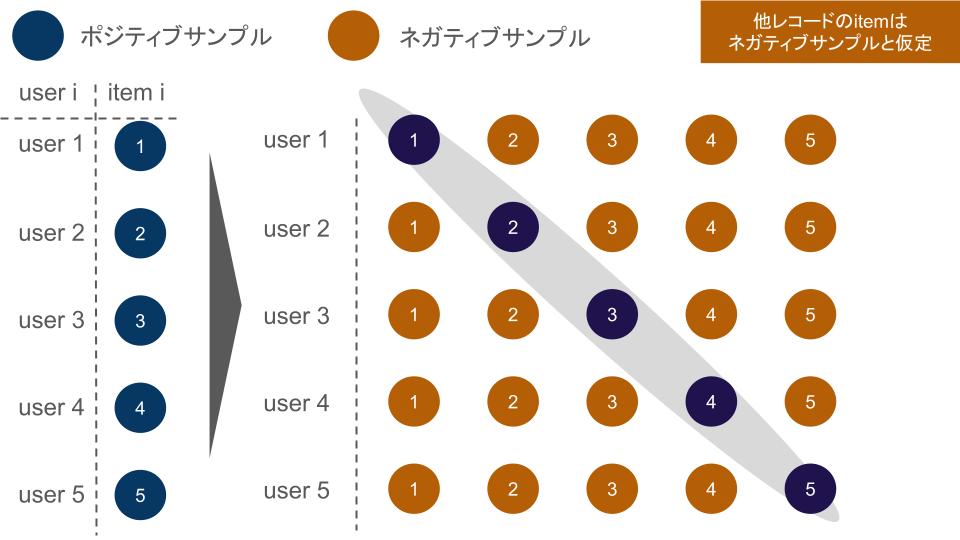
In-Batch Negative Sampling とは、あるユーザに対して「同じミニバッチ内の他ユーザの正例アイテム」をネガティブサンプルとして兼用する手法です。
この方法では、ミニバッチ内で既に計算したアイテム埋め込みを負例として流用できるため、負例のために追加でアイテムをサンプルして埋め込み計算(forward)するコストを抑えつつ、多数のネガティブと比較できます。InfoNCEでは一度に複数のサンプルを比較するため、Negative Sampleの計算コストが無視できなくなる傾向にあります。
以下は具体的な手法です。
先ほどの InfoNCE の式の文脈でいうと、ユーザ ui に対して
- 正例(ポジティブ):
- ネガティブ:
(同一バッチ内のその他のアイテム)
という対応付けになります。(図1参照)
ここからが本題です。
この In-Batch Negative Sampling + InfoNCE の構成は Two-Tower モデルの文脈において非常に一般的な構成ですが、実際のモデル開発においてはいくつか考慮すべき課題があります。
今日は、その課題の一部と対策例を議論していきましょう。
課題1: バッチサイズへの強い依存
InfoNCE Loss には、「相互情報量 I(X;Y) の下限を与える」というよく知られた評価式があります。[1]
![]()
ここで N は「1 つの正例と一緒に比較されるサンプルの総数」です。
(* 厳密には独立負例を仮定して導かれる下界であり、in-batch negatives ではその仮定が必ずしも成り立たない点に留意されたい。)
In-Batch Negative Sampling の設定では、1 ユーザあたりの比較対象はほぼ「バッチサイズ B 個」になるため、バッチサイズが小さいと、到達しうる相互情報量の下限も小さくなってしまいます。
その結果、モデルの性能がバッチサイズに強く依存するという問題が生じます。
対策例:
1. MoCo 型のメモリバンク / キュー
この問題への対策一つが、MoCo に代表されるメモリバンク(キュー)方式です[2][3][4]*。
- 過去バッチのアイテム埋め込みをキューとして保持しておき、
- 現在バッチのユーザ埋め込みと比較するときに、そのキュー内の多数の埋め込みをネガティブとして利用する
ことで、実効的なネガティブ数 Nを「バッチサイズ」ではなく「キュー長」まで拡張できます。
これにより、大きなミニバッチを組まなくても、多数のネガティブを確保しつつ学習できるようになります。
一方で、実装上のハードルは比較的高く、導入にあたっては慎重に検討する必要があります。
厳密には、最新の MoCo v3 [4] ではモデル構造の単純化(ViTへの適応)のためキュー(Memory Bank)は廃止され、SimCLRと同様の大規模バッチ学習に戻っていますが、同シリーズの重要な発展形として併記しています。*
課題2: 出現頻度に由来するバイアス
In-Batch Negative Sampling は「バッチに出てきたアイテム」をそのまま負例として使うため、バッチに登場しやすい=出現頻度の高いアイテムほどネガティブとして選ばれやすいというバイアスがあります。
その結果、人気アイテムは不当に類似度を押し下げられやすくなります。一方で、低頻度アイテムはそもそもネガティブとして登場しにくいため、学習で受けるノイズ(更新)が弱くなるという問題が生じます。
タイミーの文脈では、単なるアイテムの人気度だけでなく、エリア(地理)や職種によっても出現頻度が大きく異なるため、同様の構造のバイアスがより複雑な形で入り込みます。
対策例:
1. LogQ Correction
In-Batch Negative Sampling では、popularity bias によりスコアがサンプリング確率 (学習時に負例としてサンプルされるアイテムvの周辺確率)に引きずられ、以下の形に収束してしまいます。
![]()
ここで r(u, v) は真の関連度を表します。
そこで、ロジットを
![]()
としてあらかじめバイアス項を差し引くことで、人気度に依存しない本質的な関連度を学習させます[5]。
2. ランダムサンプリングによるネガティブ補完
In-Batch Negative Sampling だけに依存せず、別途ランダムサンプリングしたネガティブを足す/混ぜることで、人気アイテムだけにネガティブが偏らないようにする、というアプローチもあります。
この対策は比較的実装ハードルが低いです。
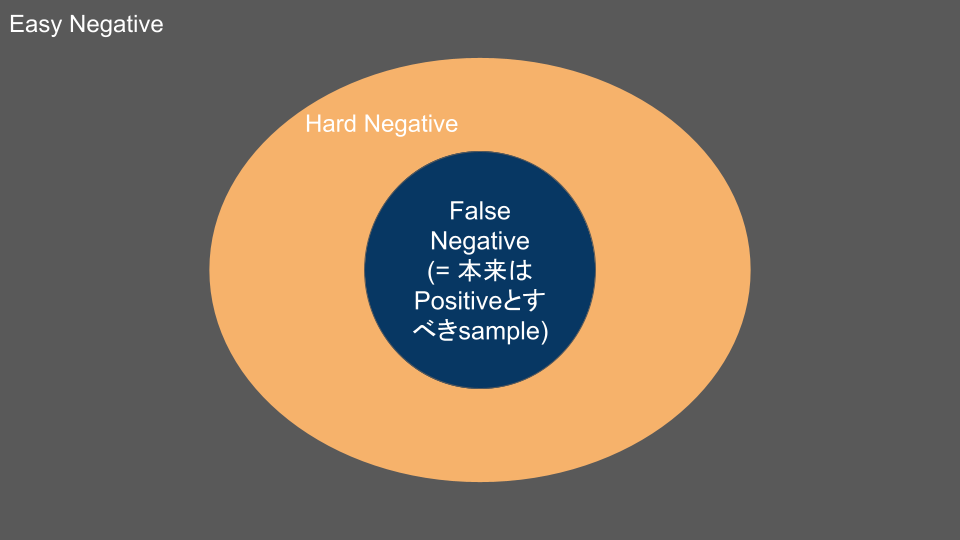
課題3: False Negative
In-Batch Negative Sampling では、本来はポジティブであるべきアイテムがネガティブ側に紛れ込む(False Negative) ことが、かなりの確率で起こります。
有効バッチサイズやネガティブ数を増やしていくほどその発生頻度も上がるため、現実的には「避けきれないが、無視もできない」やっかいな問題です。
InfoNCE では、学習が進むと多数の easy negative はほとんど loss(=勾配)に寄与しなくます。そのため、性能を上げるには hard negative をしっかり集めることが重要になります。
しかし、良い hard negative ほどポジティブとの境界付近に位置するため、hard negative を攻めるほど False Negative を混入させやすくなるというトレードオフがあります。
False Negative が多いと、
- 本来近づけたいユーザ–アイテムのペアを、loss が「離せ」と強く押してしまう
- 結果として、似たアイテム同士が不自然に遠ざかり、リコールや一般化性能を削ってしまう
といった形で、表現学習全体に悪影響が出ます。
筆者としては、False Negative の発生自体はある程度は仕方ない前提だと考えており、 「False Negative を完全に消しに行く」よりも、それによって勾配が暴れすぎないようにコントロールする仕組みを重視したいスタンスです。
対策例:
1. Debiased InfoNCE (統計的な補正)
「ネガティブサンプルの中には一定確率 π でポジティブが混ざっている」という仮定を置き、Loss の分母からポジティブ成分の期待値を差し引くことでバイアスを除去する手法です [6]。 これにより、FN を無理やり遠ざけようとする誤った勾配の発生を統計的に抑制します。
2. False Negative Masking (高スコアの無視)
学習が進むと、モデルは FN(ラベルは負だが実は正例)に対して高い類似度スコアを出すようになります。 これを利用し、バッチ内のネガティブサンプルのうち、スコアが閾値を超えた(=モデルがポジティブだと確信している)ものを Loss 計算から除外(Masking)します [7]。 「怪しいものは学習に使わない」という割り切りにより、外れ値的な勾配によるモデル崩壊を防ぎます。
一方で、閾値が恣意的になりやすく、この閾値をどのように定義するかに難しさがあります。
おわりに
ここまで、幾つかの課題とその課題に対する対策例を挙げてきましたが、モデルを学習する状況やデータによって、相応しい対策は異なります。手法をきちんと理解した上で運用することで、より良い候補生成用のベクトルを作っていきたいです。
We’re Hiring!
タイミーではデータサイエンティストをはじめ、一緒に働くメンバーを募集しています!
カジュアル面談も行なっておりますので、興味のある方はぜひお気軽にお申し込みください!
現在タイミーでは推薦エンジンを一緒に改善していくメンバーを募っております。
参考文献
[1] [1807.03748] Representation Learning with Contrastive Predictive Coding
[2] [1911.05722] Momentum Contrast for Unsupervised Visual Representation Learning
[3] [2003.04297] Improved Baselines with Momentum Contrastive Learning
[4] [2104.02057] An Empirical Study of Training Self-Supervised Vision Transformers
[5] Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations