
はじめに
こんにちは!絶賛採用中 のタイミーのDevPlatformチームの @MoneyForest です。なお、この記事は Timee Advent Calendar 2025 シリーズ2の11日目の記事です。
本記事ではタイミーの「アプリケーション定点観測会」で取り扱っているDatadogのダッシュボードを改善した件について記載します。
アプリケーション定点観測会とは
タイミーにおける「アプリケーション定点観測会」は「アプリケーションの品質に関わるメトリクス、イベント、ログ、トレース(MELT)を週次のサイクルで観測し、それぞれの事実をチーム全員で確認しフィードバックループを回すこと」を目的として行われます。
平たくいうとDatadogのダッシュボードを全員で眺め、認識を合わせたり、確認や改善のアクションを決定する会です。
このような取り組みは各社のテックブログでも散見され、SREの取り組みとしては一般的なもののように思います。(各社「SLO定例」「モニタリング定例」「パフォーマンス観測会」などさまざまな名前がついているようです。)
それぞれ何を重視するかで特色があるとは思いますが、基となる考えはおそらくSRE本の「31章 SREにおけるコミュニケーションとコラボレーション」の「31.1 コミュニケーション:プロダクションミーティング」の以下の内容に拠るところではないでしょうか。
しかし、私たちが行うミーティングの中で、平均以上に有益なものが一つあります。それはプロ ダクションミーティングと呼ばれるもので、SREチームが自分たちと他の参加者に対し、担当す るサービスの状況について十分に注意を払って明確に説明をすることによって、すべての関係者の 全般的な認識を高め、サービスの運用を改善するために行われます。概して、これらのミーティン グはサービス指向で行われるもので、直接的に個人の状況のアップデートに関するものではありま せん。このミーティングが目標とするのは、ミーティングが終わった後に、進行中のことに関する 全員の認識が同じになることです。プロダクションミーティングには他にも大きな目標がありま す。それは、サービスに対するプロダクションの知恵を持ち寄ることによって、サービスを改善す ることです。すなわちサービスの運用パフォーマンスの詳細について話し合い、それを設計や設 定、実装と関連づけて考え、問題解決の方法を推奨するということです。定期的なミーティングに おいて設計上の判断をサービスのパフォーマンスと合わせて考えてみることは、きわめて強力な フィードバックループになります。
(出典:Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy 編、澤田武男・関根達夫・細川一茂・矢吹大輔 監訳、玉川竜司 訳『SRE サイトリライアビリティエンジニアリング ―Googleの信頼性を支えるエンジニアリングチーム』オライリー・ジャパン、2017年、p.448)
これまでの会とその課題
「アプリケーション定点観測会」は概ね目的を果たしていましたが、「チームの認識が揃わない」 ということがしばしばありました。
- どこを見るかが揃わない: 会議の最初に「各自でダッシュボードを眺めて気になった点を挙げる」という時間を設けていましたが、人によって見始めるウィジェットが違うことで時間内に見切れなかったり、見る人によって解釈が異なったりしていました。
- 良いか悪いかの判断が揃わない: 例えばCPU Utilizationのようなウィジェットは、100%に達していなければOKと一瞬で判断できる一方、Y軸が100に固定されていないと自動でウィジェットが縮尺してしまうため、パッと見て判断できず無駄な時間がかかることがありました。
- 次のアクションが揃わない: メトリクスの見方が人によって違うため、「このグラフのこの変化はどういう意味か?」といった認識合わせの議論に時間が割かれることもしばしばありました。
このようなケースがときおり発生しており、会が非効率になってしまうことで気づくべき変化を見落としてしまうことは避けたいと考え、ダッシュボードを改善しました。
改善アプローチ
課題に対応する形で、3つの改善を行いました。
| 課題 | 改善 |
|---|---|
| どこを見るかが揃わない | ダッシュボードの集約 |
| 良いか悪いかの判断が揃わない | 明確なウィジェット |
| 次のアクションが揃わない | 観点の明記 |
1. ダッシュボードの集約 ─ 「どこを見るか」を揃える
プロダクトごとに似たようなダッシュボードが並んでいたので、テンプレート変数を使い集約できるようにしました。またプロダクト・非同期処理・データストアなどでダッシュボードが分散していたので、1つのダッシュボードに集約しました。
テンプレート変数とはダッシュボードに定義できる変数のことです。クエリに$をつけることで変数を参照でき、似たようなウィジェットを複数作らなくてもよくなることで保守性が上がるメリットがあります。

2. 明確なウィジェット ─ 「良いか悪いか」を揃える
ウィジェットについて「閾値に抵触していないか?」「変化はリリースによるものか?」といった点がパッとわかるようにしました。
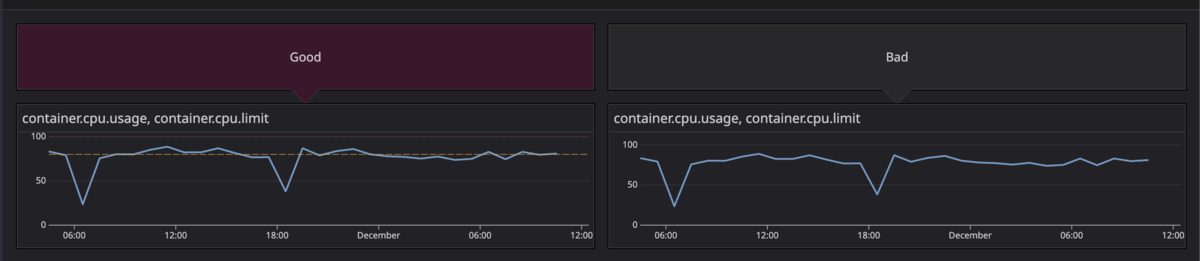
Y軸の固定とマーカー
例えばなんらかの使用率(Utilization)を見る場合、Y軸を100%に固定し、85%と100%にマーカーを引くことで、一目で状態が把握できるようになります。
マーカーを設定する理由は、意思決定をブレさせないためです。たとえばある日ではCPU使用率が80%のときに「なんかやばくね?」と判断して調査したのに、それより上の85%のときは「まだ余裕あるし対応しなくていいか」となってしまうことがあります。人によって、あるいはその日の気分や残り時間によって判断基準が変わってしまうことがあるのです。
では「CPU使用率が85%を超えた場合は一次調査する」と決めるだけでいいかというと、見逃してしまったり忘れてしまったりのリスクが残ります。マーカーで線を引いておけば「85%を超えたら調査や対応を検討する」との決めが視覚的に表現でき、ブレがなくなります。
マーカーを2つ引く理由にも意図があります。85%(ワーニング) はスケールアウトやスケールアップを検討する目安です。この段階で気づければ、余裕を持って対応できます。観測会では主にこちらを取り扱います。100%(クリティカル) はアラートが発報されるラインであり、すでに問題が顕在化している状態です。通常こちらはアラートによって取り扱うため、観測会では事後的な確認になります。この2段階にすることで、判断がしやすくなります。閾値自体が大切ではなく、「対応を開始するライン」と「抵触したら問題になるライン」を常に表示しておくことが大切です。
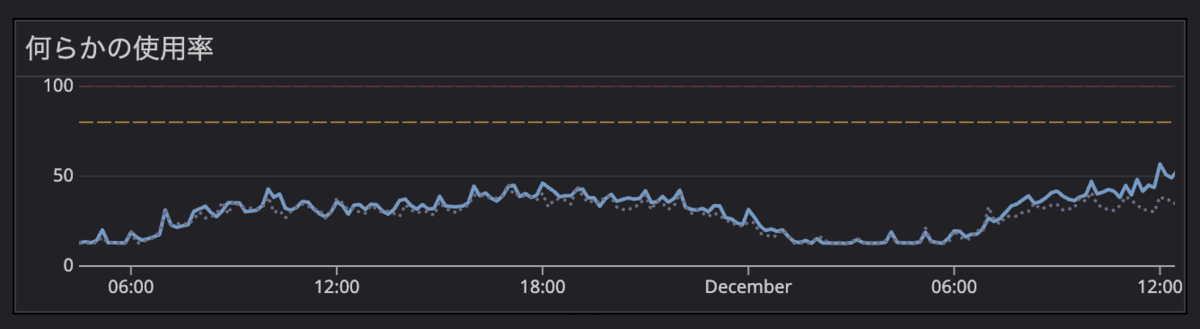
前週比のオーバーレイ表示
Datadogのcalendar_shift関数を使って、前週のデータを点線でオーバーレイ表示しています。これにより「先週と比べてどうか」が一目でわかります。
そもそも前週比がないと何が困るのでしょうか?グラフを見ても「この数値は高いのか低いのか」が判断できません。例えばエラー数が100件あったとして、それが普段通りなのか異常なのかは、比較対象がないとわからないのです。結果として「なんとなく大丈夫そう」という曖昧な判断になったり、正常なのに異常と誤認して無駄な調査をしてしまうことがあります。
「前週比」という点にもポイントがあります。前日比だと曜日による変動に惑わされます。例えばリクエスト数が平日と休日で大きく異なるプロダクトの場合、月曜と日曜を比べてもあまり意味がありません。前月比も同じく週が一致しない場合があるので、使いづらいです。そのため「前週の同じ曜日」との比較がちょうど良いと考えました。この辺りはプロダクトの特性にもよって適切な設定が変わってくると思われます。
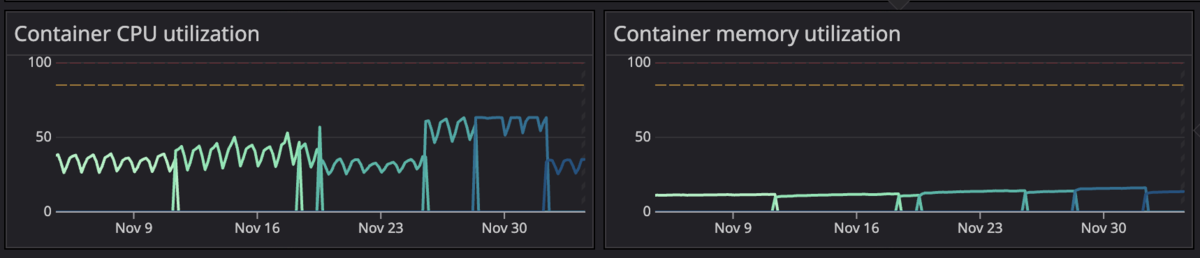
リリースとの関連付け
メトリクスに変化があったとき「それはいつのリリースが原因か?」を特定したいことがあります。リリースと紐づいていないと、変化の原因を探すために別途デプロイ履歴を確認する手間が発生します。
用いるメトリクスもそういった観点を踏まえて選びます。CloudWatchのaws.ecs.cpuutilizationメトリクスはECSサービスレベルしかわからず、どのコンテナを改善すべきか、リリースとの関連がわかりづらいです。Datadog AgentサイドカーのFargateメトリクスで使用率を計算し、task_versionでグルーピングすることでリリースによる使用率の推移を観測できます。(デプロイのイベントをDatadogに送信するのもありかと思います)
sum:ecs.fargate.cpu.usage{$service_name} by {task_version}
/ sum:ecs.fargate.cpu.task.limit{$service_name} by {task_version} * 100
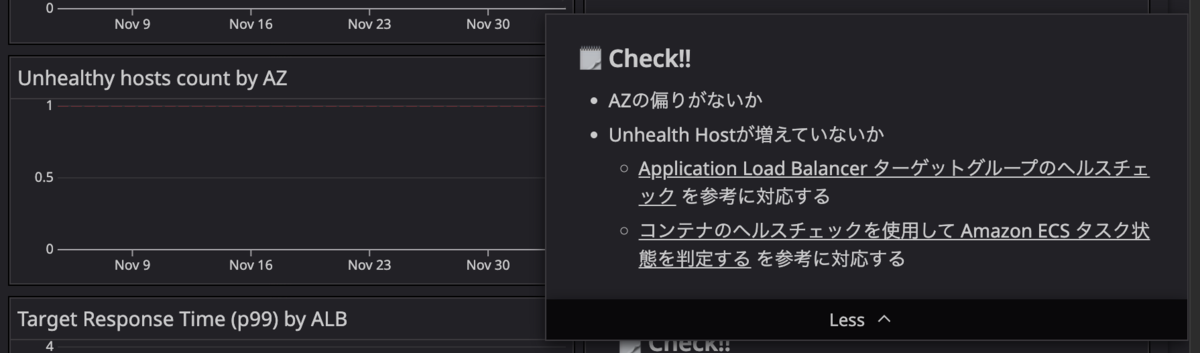
3. 観点の明記 ─ 「次のアクション」を揃える
ウィジェットの横にメモを必ず設けるようにしました。
メモがないとグラフが異常なように見えても「で、どうすればいいの?」となってしまうことがあります。自分が詳しければ問題ない、または詳しい人がいれば説明してくれますが、その人が休みだと判断できません。メモに「異常時は〇〇を確認する」と書いてあれば、誰でも次のアクションを取れます。ネクストアクションについて書きすぎると目が滑ってしまうので、あくまで簡単な記載にとどめます。ランブックへのリンクにするのもよいでしょう。
逆にメモが書けないような「とりあえず出してみている」ウィジェットは今回を機にバッサリ整理しました。そのようなウィジェットは時間が余った際に探索的に見るものと位置付けています。
余談ですが、スキルアップやバックログアイテムの発見につながるため探索的に見ることも重要だとは考えています。一方で、「予防」のアクションを取りたいのか「発見」のアクションを取りたいのかで適切なやり方は異なるため、会を分けるべきと考えています。
メモには「メトリクスの説明(どういったメトリクスで、どういった事象を引き起こすか)」「望ましいメトリクスの状態」「異常時に取るべきアクション」などを簡単に記載しています。
実際のダッシュボードでは以下のような形式でメモを記載しています。
## 🗒️ Check!! - 前週比(点線)で異常に増えていないか - アプリケーションのエラーなのでLogsから原因を確認
## 🗒️ Check!! - Task Limit(赤線)に抵触してないか - 抵触している場合スケールアップ or 性能改善が必要
## 🗒️ Check!! - 前週比(点線)で異常に増えていないか - AWSの「Troubleshoot your Application Load Balancers」のドキュメントを参考に対応する - 4xxが跳ねている時はWAFがブロックして403を返していることが多く、 その場合は攻撃を弾いているので特に問題はない
おわりに
このような工夫をすることで、「どこを見るか」「良いか悪いか」「次に何をするか」について以前よりチームの認識が揃うようになりました。認識合わせに費やしていた時間が減り、その分を「なぜこの変化が起きたのか」という深掘りの議論に当てられるようになっています。
一方で、観測会ではアプリケーションのダッシュボード以外にもセキュリティやコストについても確認しており、「人によって見始めるウィジェットが違うことで時間内に見切れない」という課題は以前より緩和したものの、解消されたとは言い難い状態になっていますので、引き続きの改善を行っていきたいです。(今期からコストは一部別の会議に切り出しています。)
今回ご紹介したダッシュボード改善のプラクティスが、みなさんのチームの参考になれば嬉しいです。
タイミーでは一緒に働くエンジニアを募集しています!興味のある方はぜひカジュアル面談でお話ししましょう。
またね〜