はじめまして!フロントエンドエンジニアの樫福 @cashfooooou です。
タイミーでは Next.js × TypeScript で toB 向け管理画面を作成しています。 この記事は、toB向けの管理画面の開発時に筆者が気づいたコンポーネント間の責務の明確化の必要性と、 TypeScript の型を用いて責務の分割をサポートする方法の紹介しています。
背景
利用者の様々なニーズに応えるために、toB向け管理画面には様々なページが実装されています。 2つ以上のページを実装していると、それぞれのページで実装の粒度がバラバラになることがあります。
- 一方ではフックの中で実装していたようなロジックが、他方ではコンポーネントで実装されている
- あるページのコンポーネントは複数のファイルに分割しているけど、こちらのページでは巨大な一つのファイルで実装が完結している
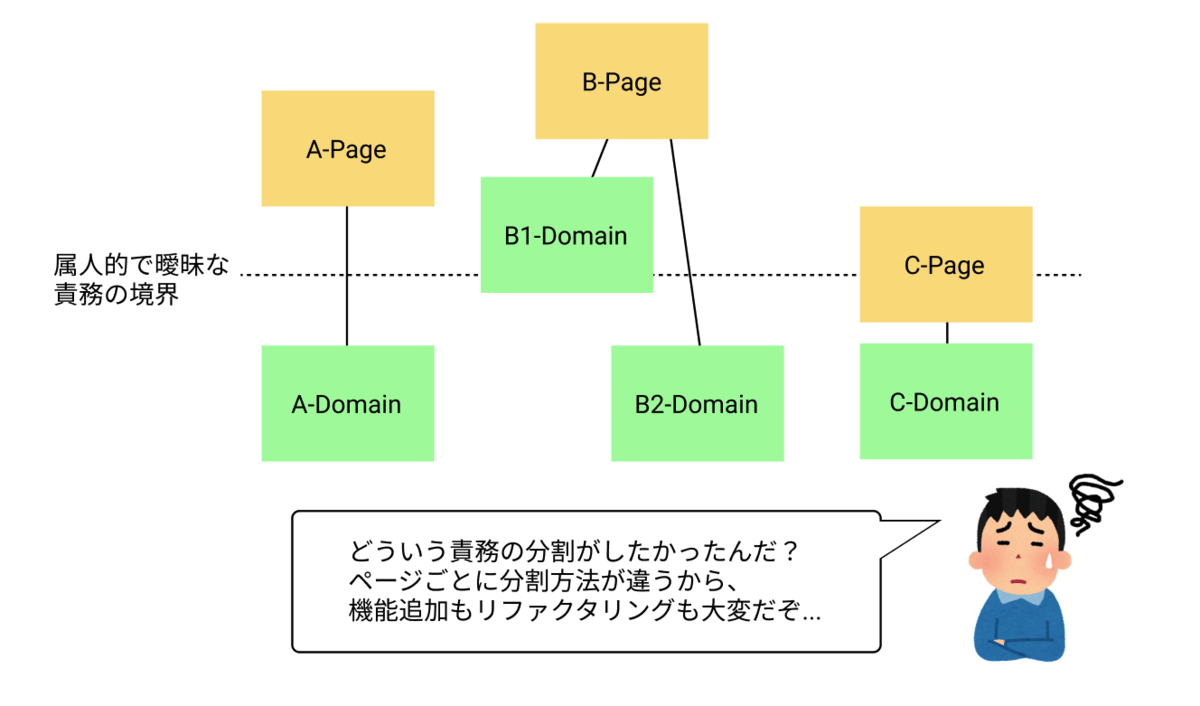
Next.js は pages/ 配下にファイルを追加すると自動的にルーティングが作成されますが、ディレクトリ構造についてのそれ以外の制約はありません。
実装やレイヤ分けは実装者に委ねられており、責務の分割をしっかりやるためには実装もレビューも "人が頑張ってやる" ことが求められます。
例えば、Atomic Design というコンポーネントの粒度とその依存関係を定義したデザインフレームワークが存在します。 Atomic Design のようにコンポーネントを細かく分割する際には実装者やレビュー担当者によって責務が精査される必要があります。 責務の分割を適当にやったり人によって判断がぶれたりすると、システム全体を見た時に一貫性が失われてしまいます。
コンポーネントの責務が揃っていると次のようないいことがあります。
- 設計思想に則ってロジックが分割されるのでコンポーネントが単一責任を担うようになる
- 抽象化、具体化をレイヤを意識して行うので結果的に再利用性が高くなる
- Unit Test や Visual Regression Test の実装や管理のコストが小さくなる
- コーディングガイドラインが整い、実装者が迷うことなく書くべきコードに集中できる
しかし、新しいコンポーネントを実装するたびに人の判断でコンポーネントの責務が適切に分割されているかを判断するのは簡単ではなく、実装やレビュー担当者の力量や考え方に依存します。 結果として、システムが入退社等に伴うエンジニアの交替に弱かったり考え方の変化によってシステム全体で方針が統一できなかったりします。
責務の境界の曖昧さを何か機械的な方法でなくせると、属人的ではなくなり一度決めた方針を貫けるので嬉しいです。
実現方法
コンポーネントの受け取るデータの型を基準にして、適切なコンポーネントの責務の分割を実現します。 適切な型を用いて責務を表現し、型を中心にして一貫性のある責務が明確になっている状態を目指します。
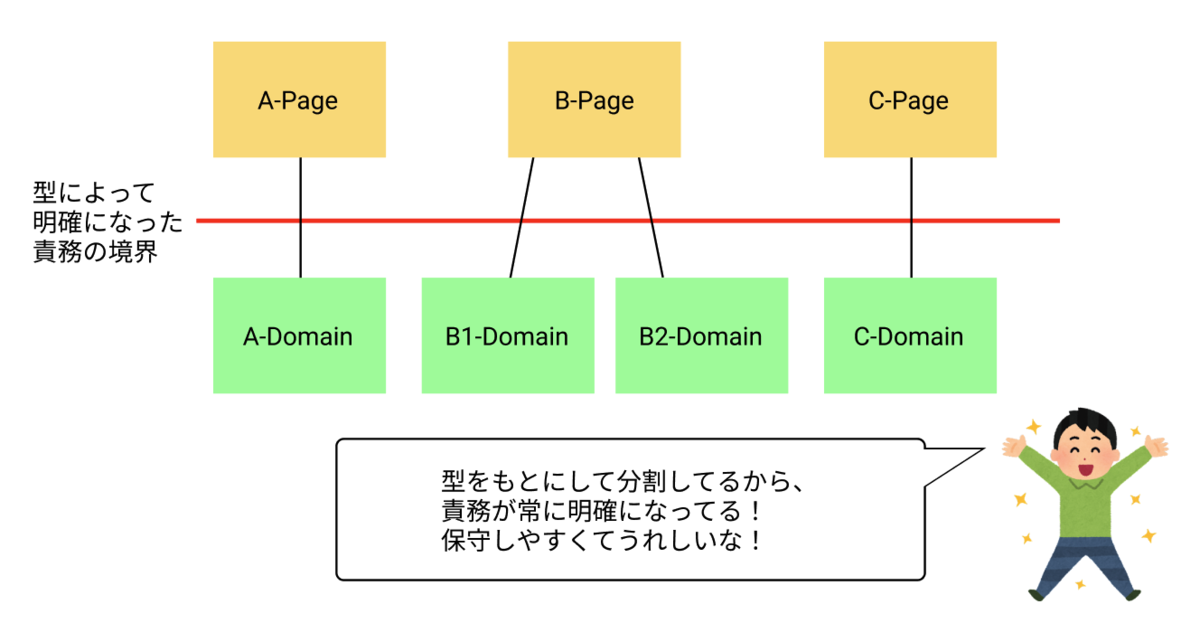
責務を表現する型を作るために、コンポーネントが「何をすべきか」と「何をしてはいけないか」を明確にしてみましょう。
例として、 Atomic Design で 何かのデータをリスト形式で表示する UI を実装することを考えてみましょう。 Atomic Design は 5段階の要素(atoms、molecules、organisms、templates、pages)のうち、 organisms - molecules 間の責務について取り上げてみます。 リストの形式のデータを持つ時はそれぞれの責務のうち、とくに「何をすべきか」は次のようになります。
- organisms
- リストの繰り返しの扱いを担うべき *1
- molecules
- リスト中の単一のデータについて、そのデータの描画を担うべき
一方のコンポーネント の「何をすべきか」がわかると、 他方の「何をしてはいけないか」も見えてきます。
- organisms
- 単一データの描画について担ってはいけない
- molecules
- リストの繰り返しを扱ってはいけない
「何をしてはいけないか」という制約を明確にすることは、責務の分割にとても有用です。
実装レベルで 、molecules が受け取るデータの型が何かのリストの形式 Array<T> になっているならば責務の分割がうまくできていないことを疑うことができます。
以降では、責務の分割のための具体的な型とそれを用いたコンポーネントの実装まで提示していきます。
具体的な例: API のレスポンスを表示するコンポーネント
一般的なアプリケーションの例として、 RESTful API のレスポンスを表示するページの実装を挙げます。
こちらのデモ と併せて読んでいただけると、より理解が深まると思います。
以下に定義するコードは src 以下に配置されています。
API クライアントはモックを使用しており、取得成功と取得失敗(とそれぞれの取得中)の動作を確認できるようになっています。
API クライアントの定義
次のようなユーザの投稿を扱う型 Post と API クライアント apiClient を使用します。
以降では、ユーザの投稿を一覧表示する PostPage の実装を考えます。
type Post = { postId: number; content: string; postedAt: string; }; const apiClient = { fetchPosts: async (userId: number) => { const { data } = await axios.get<Post[]>(`https://xxx.com/api/{userId}/posts`, { params: { userId } }); return data; }, };
ディレクトリの責務の定義
コンポーネントのディレクトリとして「pages」「domains」というものを作ることとします。
それぞれの責務として「何をすべきか」と「何をしてはいけないか」は次のように定めます。
- pages
- domains
ここでいう「API レスポンスの状態」というのは、取得時の待ち状態やエラーを指しています。 責務を明確にすること、とくに「してはいけない」を明確にすることによって、本来の責務に集中して実装することができます。
型の定義
API レスポンスの状態を扱うために、次のジェネリック型 ApiState を定義します。
type ApiState<T> = | { type: 'loading'; } | { type: 'error'; errorMessage: string; } | { type: 'success'; result: T; };
domains の責務の 2つ目である「あくまでデータを扱うだけで API レスポンスの状態に依存してはいけない」 を満たすことはとても簡単で、ApiState 型のデータを受け取らないとするだけで良いです。
これだけで、実装者もレビュー担当者も domains のコンポーネントのプロパティに注目することで不適切な責務の分割が行われていないか確認できます。
さらに ESLint などで 「domains のディレクトリ配下での ApiState のインポートを禁止」というルールを定めれば、機械的に判断することすら可能です。*2
apiClient を用いて Post[] 型のデータを取得するフック、 usePostLists を次のように実装します。
// usePosts は userId を受け取って ApiState<Post[]> を返すフック interface IUsePosts { (userId: number): { postsState: ApiState<Post[]>; }; } export const usePosts: IUsePosts = (userId) => { const [posts, setPosts] = useState<Post[] | null>(null); const [error, setError] = useState<string | null>(null); // エラーになったとき、かつエラーの時のみ string型のエラー文になる useEffect(() => { (async () => { try { const result = await apiClient.fetchPosts(userId); setPosts(result); } catch (e) { setError(errorToString(e)); } })(); }, [userId]); const postsState: ApiState<Post[]> = error ? { type: 'error', errorMessage: error } : posts === null ? { type: 'loading' } // エラーでなく、かつ取得前なので取得中 : { type: 'success', result: posts }; return { postsState }; };
フックについても、API を扱うフックの返り値を「ある型 T に対する ApiState<T>」とすることで、API レスポンスを扱うという責務を明確にすることができています。
この時点で、pages の責務を満たす実装はとても楽になっています。
Post[] 型のデータを受け取って投稿一覧を表示する domains のコンポーネント PostList、エラーメッセージを受け取ってエラー状態を表示するコンポーネント ErrorView、読み込み状態を表示するコンポーネントLoadingView という 3つのコンポーネント(実装例は省略)を用いて、pages/PageListPage は次のように実装できます。
const PostListPage: React.FC<{ userId: number }> = (props) => { const { postsState } = usePosts(props.userId); if (postsState.type === 'success') return <PostList data={postsState.result} />; // postsState.result の型は Post[] if (postsState.type === 'error') return <ErrorView errorMessage={postsState.errorMessage} />; return <LoadingView />; };
たったこれだけのコードで pages の「コンポーネント内で API レスポンスを受け取り、状態に応じて表示を変える」という責務を満たしています。
また、 domains である PostsList の「API レスポンスの状態に依存してはいけない」という制約も満たされていることがわかります。
型を導入することで、その型を中心に責務が明確になっています。 実装者もレビュー担当者も、この型の情報を責務の分割の指標として使うことができます。
ライブラリを使用する際の利点
責務が明確になっている状態であれば、実装の一部をライブラリに差し替えや使用するライブラリを置き換えが影響範囲を小さくすることで容易になります。
たとえば、React 16.6 で実験的に追加された機能の Suspense は、コンポーネントが API レスポンスの状態に依存しないようにしているという点において上記の実装とよく似た用途で使用することができます。
紹介したような実装方法をとっていて Suspense を使った実装に切り替える場合、 pages と一部のフックを修正するだけで他への影響はほぼ発生しないです。
実装時の注意
これまでに出した例は非常にシンプルなものなので簡単な実装で済みました。 しかし、現実にエンジニアリングで向き合う問題は必ずしもシンプルではないです。
あるタイミングで責務を満たす型を作成したとしても、他の機能の実装中にエッジケース(例外)が見つかることがあります。 エッジケースに対してアドホックに型の修正を行うと、責務の本質から大きく逸れた歪な型になってしまいます。 他方でエッジケースを例外的に扱う癖がついてしまうと、責務を担う型自体が形骸化してしまいます。 型自体を常に精査し続け必要に応じて更新していくことで責務が明確な状態を保つことが、システムの質を高い状態で保つには不可欠です。
しかしながら、無自覚に責務から逸脱するコードを書く心配がなくなり、型の修正がそのまま責務の再定義になる点は、型の恩恵を受けていることを強く実感します。
まとめ
この記事では、型を用いたコンポーネントの責務の明確化の方法について紹介しました。 責務を表現する型を用いて、属人的でない責務の明確化が可能になります。
実務で実装をしていると、UI や UX、ビジネスロジックなど、集中しなければならないことがたくさんあって大変だなと感じます。 紹介したような取り組みは本当に集中しなければならないことに集中することにとても役に立ちます。
今後も、システムの品質や開発効率を考えながら開発に取り組んでいきます。 また面白い取り組みができれば紹介したいです。
*1:いかなるケースでも organisms が Array
*2:ESLint で自作ルールを作る上で、こちらのページがとても参考になりました https://zenn.dev/nus3/articles/b2bc110efd0887442c11