はじめに
初めまして、タイミーのDRE (Data Reliability Engineering) チームの土川(@tvtg_24)です。
本記事ではデータ品質の保守に着目してここ1年くらいで試行錯誤したことを振り返っていきたいと思います。
対象にしている読者は以下の方々です。
- データ品質について考えている方
- データ分析の品質担保に困っている方
- ETLからELTへの基盤移行を考えている方
この記事は Data Engineering Study #11「6社のデータエンジニアが振り返る2021」 - connpassで発表させていただいた内容を詳細に説明したものになります。
登壇スライド: データ基盤品質向上のための一年 - Speaker Deck
動画: https://youtu.be/q9HA1S3vmcE?t=7578
以前のデータ基盤
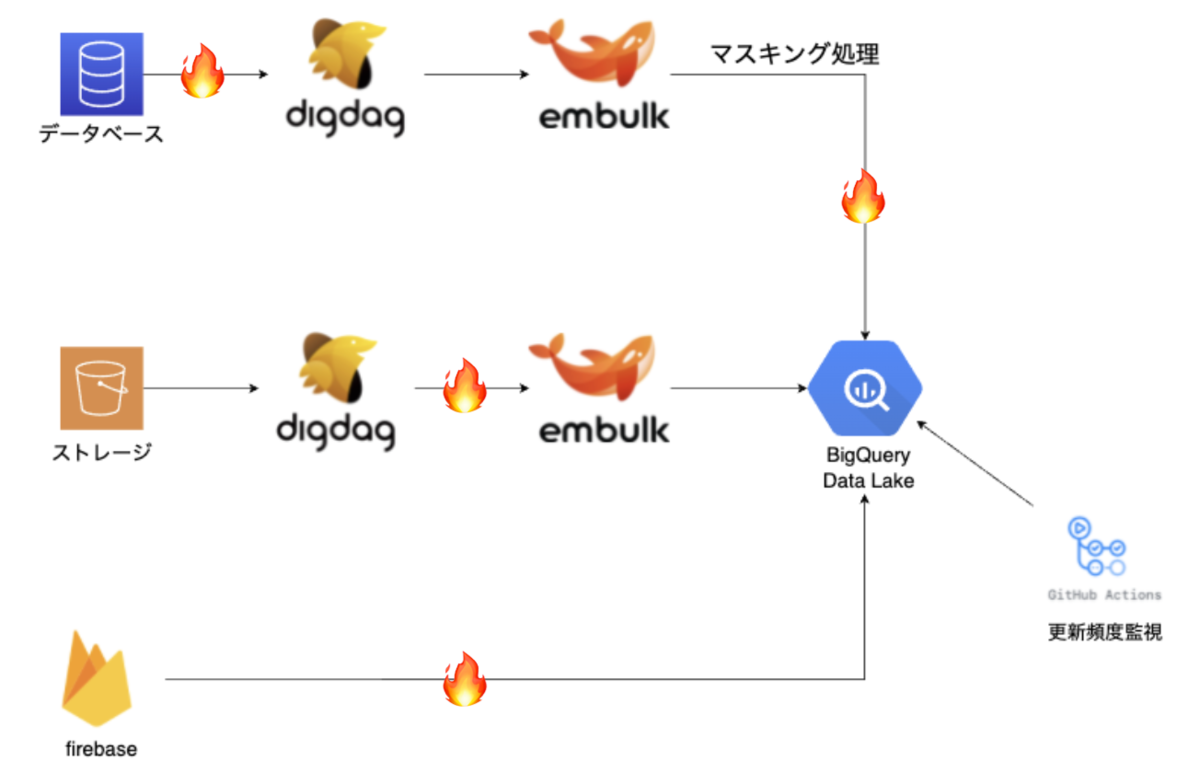
点在しているデータソースを統合した分析するためにEmbulk, Digdagを中心に用いて1年前に構築し終えたデータ基盤がこちらになります。

1番左の各種データソースからEmbulk, Digdagを用いて、BigQueryにデータを収集し、Redashやデータポータル、BigQuery上で分析を行ってもらっていました。
EmbulkはデータパイプラインにおけるETL (Extract, Transform, Load) を差分更新で実行し、T処理では主に個人情報のマスキングなどを行っていました。
これでデータ基盤はしばらく安定すると思っていたのですが、すぐ様々なエラーに遭遇することになります。
3つの問題解決と振り返り
以降ではタイミーで起こったデータ品質に関する問題解決を時系列順に紹介していきます。登場するツールの詳細な説明は省き、問題を解決するための意思決定、設計を中心に取り上げ、振り返りを行います。
問題1: データパイプラインの更新遅延
データ基盤を運用し始めてすぐ、BigQueryやBIツールの使用者からデータの更新が遅れているとの報告が多数入るようになりました。
報告が入った際にはすでにどこかの分析で重大な問題が起こっていることが多く、DREチームがすぐに対応することが多かったです。
このような事象が多く起こると、分析者はデータの品質にいつも不信感を抱きながら分析をすることになりますし、DREチームとしても新規の開発をストップして障害対応をすることが多くなるので、お互いにとっていいことはありません。
いくつかデータパイプラインにバグ監視を入れていたのですが、ETLの過程、インフラなど監視すべき部分が多く、全てのデータパイプラインをカバーすることは不可能でした。
解決策
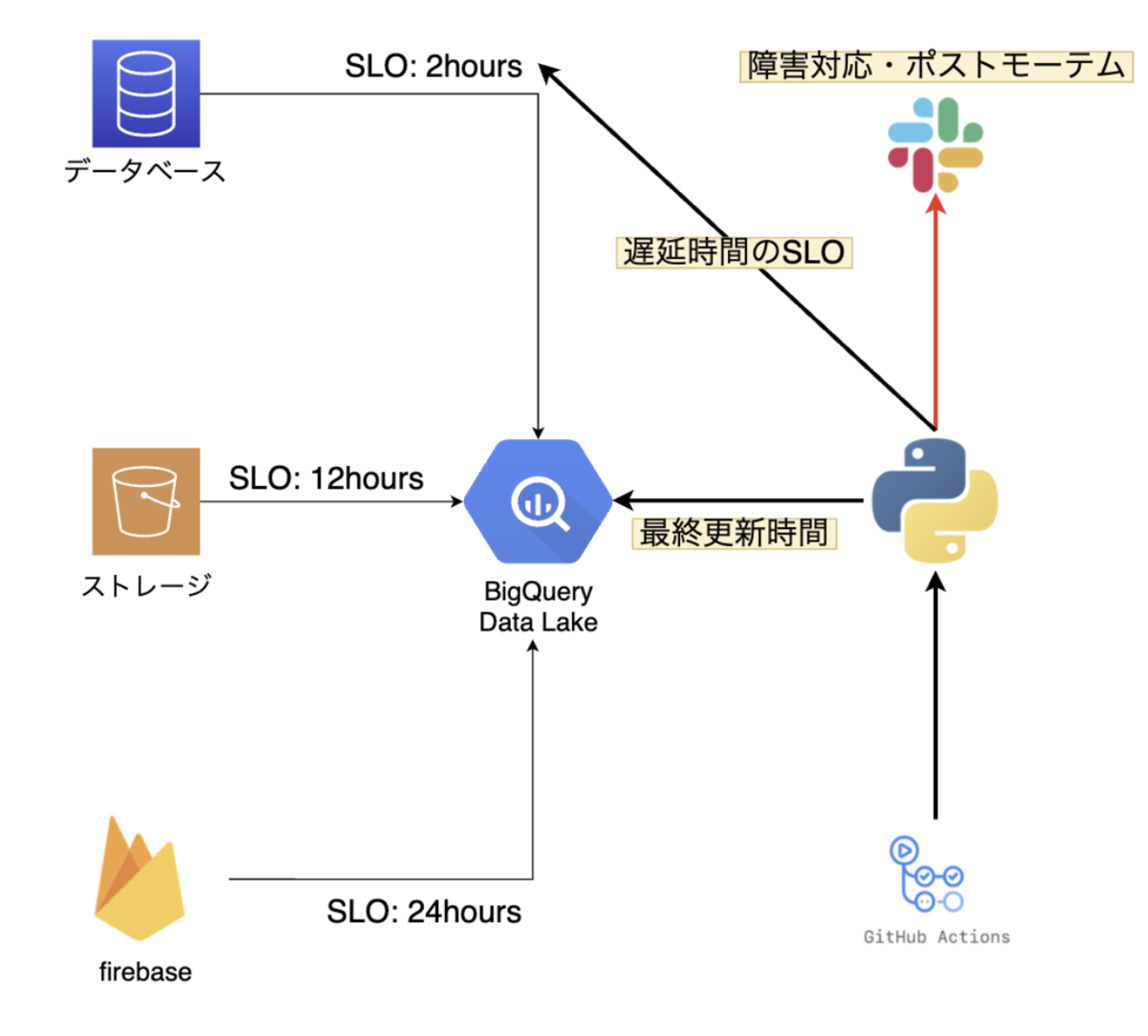
DREチームと分析者との間で、ソースデータごとの更新頻度に関するSLAを結び、適時性の監視システムを導入したことで解決しました。
適時性をSLIとして定義し、SLA, SLOを以下のスライドの定義にしました。
例えばデータソースAに関する適時性のSLA, SLOはそれぞれ1日、2時間と定義し、SLOをSLAより厳しめにすることでSLAをしっかり保守できるようにします。

適時性の定義はDMBOKという本を参考にしています。一般的なデータ品質の定義については以下の記事にまとめてありますのでぜひ参考にしてください。
DMBOKとデジタル庁を参考にデータ品質について調査、考察してみた - Qiita
実装
適時性監視システムはPythonのコードをGithub Actionsで定期実行することで実現しています。
具体的には以下の手順で実装されています。
- 各データソースごとのSLOを定義
- BigQuery上のテーブルの最終更新時間をそれぞれ取得
- テーブルの$最終更新時間 > 現在の時刻 - SLO$を比較し、この式がfalseであればSlackでDREチームに通知
BigQueryの最終時間の取得にはこちらを用いています。
google.cloud.bigquery.table.Table — google-cloud-bigquery documentation
振り返り
- 適時性に関するSLI, SLA, SLOの導入により、SLOを破った段階でDREチームが障害対応をするので分析者からの報告の前にバグの解決が可能になりました
- SLO, SLAを破らない限りはDREチームは障害対応しないので、障害に対して即対応することなく、新規開発と障害対応のバランスがうまくとれるようになりました
- SLAを破った際にポストモーテムをすることでデータパイプラインのコード品質、障害対応のフローなどの品質も向上しました
問題2: 分析チームへのクエリ修正依頼の増加
タイミーではRedashの権限が全社員に付与されています。そのため、全社員が自発的にクエリを発行し、実行し、スケジューリングを行っていてデータ活用が盛んです。しかし、間違ったクエリや古い定義のクエリを再利用してしまうことで意思決定の誤りが発生することも少なくありませんでした。
分析チームにはそれらのクエリの修正依頼が多数きており、会社の人数が増えるにつれ、依頼が増加していくことは自明でした。

解決策
この問題にはLookerを導入することで対応を試みました。Redashでは各個人が個別で分析指標のクエリを書いていましたが、Lookerはあらかじめ管理者が分析指標を定義し、一元管理することができます。そうすることで分析者は定義された指標をGUI上で選択するだけで分析やダッシュボード作成ができます。
Lookerの導入により、Redashで行われていた分析の品質を高くできるため、RedashからLookerに移行することでクエリ修正依頼の削減を目指しました。
LookMLはコード管理もできるため、指標の定義をバージョン管理することもできます。また、LookMLで定義した一部の定義をBigQuery側に戻し、BigQueryに集計テーブルを作成することもでき、これを再び他のBIツールで参照することでBIツール全体のデータ品質向上が見込めるDWHを構築することもできます。
タイミーではDREチームの自分と分析チームの方の計2人でLookMLの実装をし、重要な指標の繋ぎ込みを3ヶ月くらいかけてやりました。
実装に関してはディレクトリ構成や、モデル構成のベストプラクティスが各社で異なるのでかなり試行錯誤しましたが、Lookerのサポートやコミュニティの知見を借りながら進めることができました。
実装
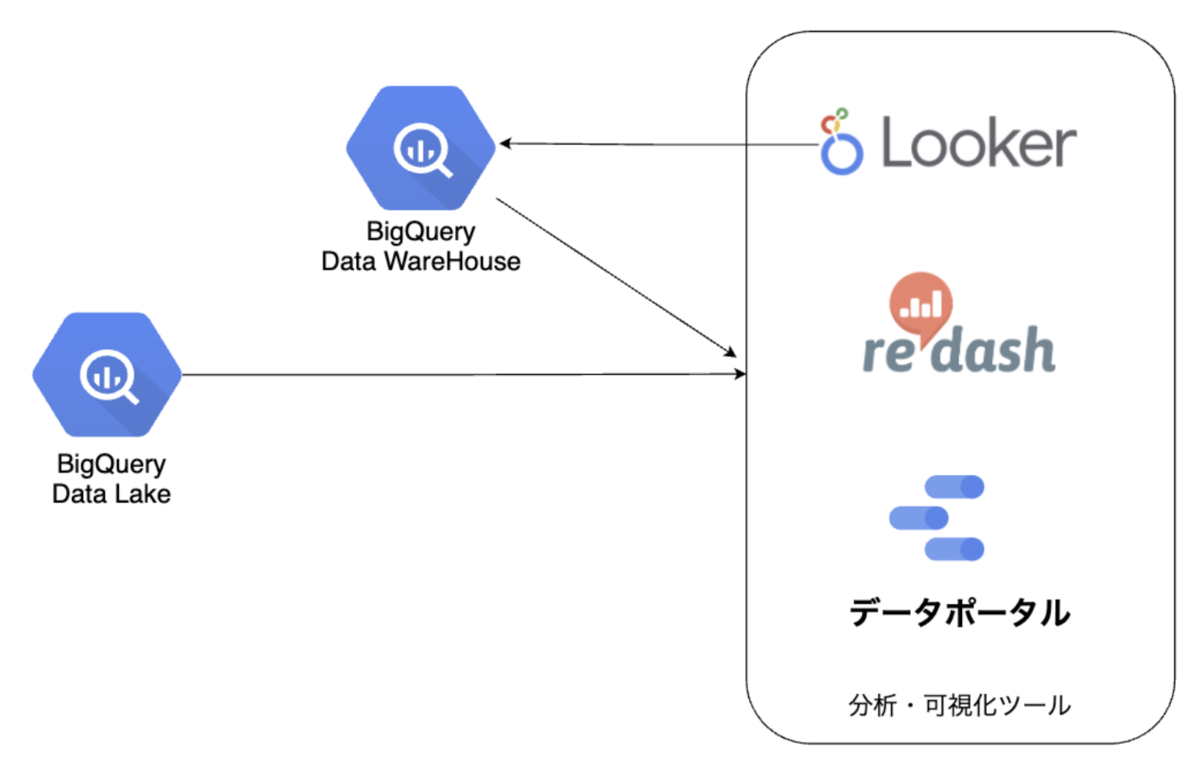
具体的な実装は以下のようになっています。様々なデータを収集しているDatalakeを、LookMLによる実装でLookerに繋ぎます。LookMLの詳細は以下になります。
集計処理が重たい指標があり、分析結果の取得までに時間がかかることがあります。これらの指標はDerived TableとしてLookerからBigQueryのDWH用データセットに永続化することで解決しています。Derived Tableの詳細は以下になります。
振り返り
Lookerの導入により、重要な指標に関しては簡単に分析とダッシュボード作成ができるようになりました。また、集計処理が重たい指標に関してDerived Tableを用いてBigQueryに永続化することで、対象の分析をする際に各BIツールにかかる負担を軽減することができました。
実際にやってみるとRedashをLookerに移行する作業は予想より大変でした。Lookerには1つ1つ指標を裏側で定義する必要があるので、Lookerで定義されていない指標を含むRedashのダッシュボードに関してはそもそも移行することができません。また、移行すべきダッシュボードと不必要なダッシュボードの選定をするために、様々な部署を巻き込んだり、ダッシュボードのメタデータ集計をする必要もあります。
こちらは未完了なため、2022年の課題として取り組んでいきます。
問題3: ETLパイプラインにおける加工処理の負債
個人情報マスキングなどの加工処理をEmbulkで行っていました。データ量やデータパイプラインが増えるにつれ、データ加工がEmbulkに依存していることで様々な負債が溜まってしまいました。
Embulkによる加工はアプリケーションが用いるデータベースが主なデータソースになっています。データベースのテーブル数は多く、全てのテーブルに対して同じ加工処理をかけていたので、テーブルやデータの増加と共に加工処理のロジックが膨れ上がり、コード量も増加します。そうなると、Embulk内で閉じている加工処理は分析チームから把握しづらいものとなり、DREチームとしてもデバッグがしづらくなりました。
また、Embulk以外のデータ転送ツールであるtroccoなどを用いて転送されるデータソースにも個人情報が含まれるため、マスキングをする必要が生じました。Embulkとtroccoそれぞれで加工処理を行ってしまうと、コードの共通化やコード管理がしづらくなってしまいました。
解決策
この問題の解決には加工処理を転送中に行うのではなく、転送後に行うELT基盤の構築が必要となります。ELT基盤により加工処理が一元管理でき、加工処理のロジックも分析チームから把握しやすくなります。ELT基盤を実現するツールは多く存在しますが、我々はdbt Cloudを選びました。
我々の要件としては、2人チームであることから導入コスト、メンテコストが少ないこと、事例が豊富であること、キャッチアップコストが少ないことなどがありました。
比較したツールでは特にDataformとdbt Cloud、dbt CLIに注目しました。
Dataformが良い点としては、GCPの傘下に入っていることや、無料で利用できることがありますが、dbt Cloud, dbt CLIと比べ導入事例が少なく、コミュニティが狭いため、今回は採用を見送りました。dbt Cloudはdbt CLIと比べ、5000円/人月のコストが発生しますが、コストを踏まえてもインフラやスケジューラがフルマネージドであり、メンテコストが少ないことが我々の要件を満たすため、dbt Cloudを導入することにしました。
dbt Cloudにより今までETL構成だったデータパイプラインをELT構成に変更し、EL処理はEmbulkやtrocco、T処理はdbt Cloudと、役割を分担することができます。
またdbt Cloudは加工処理の様子をドキュメント化することができたり、SQLライクな言語で書かれているため、分析チームがどのような加工をしているかを把握しやすいです。テストの機能も豊富でDREチームが開発に安心して取り組むこともできます。
ツールの選定には、ADR (Architectural Decision Records) というフレームワークを用いました。ADRのフォーマットを用いて機能要件、非機能要件を洗い出し、ツールを比較し、関係者の合意を得ました。
Architectural Decision Records | adr.github.io
実装
BigQueryのプロジェクトとしては、加工処理をしていないデータを保存するためのDataLake用プロジェクトと、加工処理後のデータを保存するDWH用プロジェクトの2つを用意する必要があります。
DataLake用プロジェクトは最小限の人がアクセスできるようにGCPのIAM構成を調整しました。
Embulkのマスキング実装をdbt Cloudに全て移行しました。dbt Cloudの加工処理自体はデータ転送後に行いたいため、Digdagワークフローの最後の1ステップでdbt CloudのAPIを叩くことで加工処理を実行しています。
今までのEmbulkの加工処理は全テーブルに対して処理をかけていましたが、dbt Cloudの実装では加工が必要なテーブル、カラムのみに対して処理をかけています。

振り返り
今回はADRのフォーマットでツール選定をし、3ヶ月後に選定結果の評価をしました。ADRにより、ツール選定の意思決定が綺麗に残せたこと、関係者への合意が取りやすかったこと、ツールを選定するだけで終わるのではなく、数ヶ月後にその結果の評価ができました。
dbt Cloudの導入でELT構成が実現したことによって、どのパイプラインから届くデータにもdbt Cloudで加工処理を行い、加工処理ロジックも一元管理できるようになりました。
dbt Cloudにはデータ品質に関するテストが用意されていて、not null制約などのテストが簡単に実行できます。この辺りも守るべき品質を定義しつつ、上手に使っていこうと思っています。
これからの品質に関する改善
ここ一年に取り組んだ3つの品質改善について紹介をしてきました。
最終的なデータ基盤構成図は以下のようになりました。

まだまだ品質における課題はたくさんあり、2022年にトライしていきたいことはいくつもあります。
例えば、データ品質におけるSLIは適時性だけでは足りず、データの中身の重複、欠損などの品質に関する指標を定義して保守していく必要があります。また、DWHの生成に現在Lookerとdbt Cloudの使用をしていますが、これらの役割を定義し、DWH, データマートを上手に構築していく必要もあります。
また、弊社は機械学習の導入が本格的に始まっていくので、MLOps基盤の品質担保もしていく必要があります。
最後に、DREチームは現在2人チームでチームメンバーを募集中です!
応募お待ちしてます!
meetyでのカジュアルなお話もお待ちしてます。