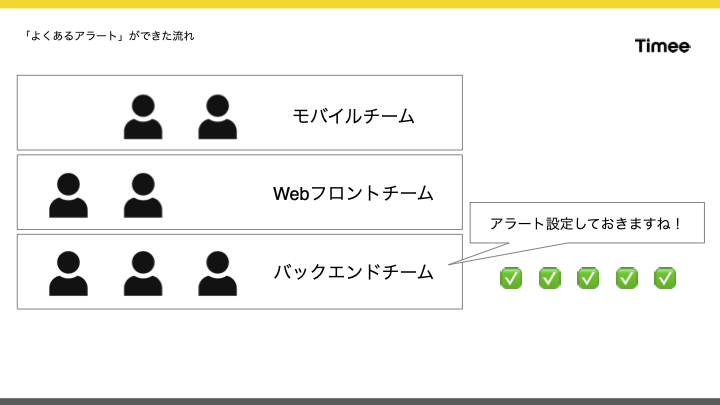
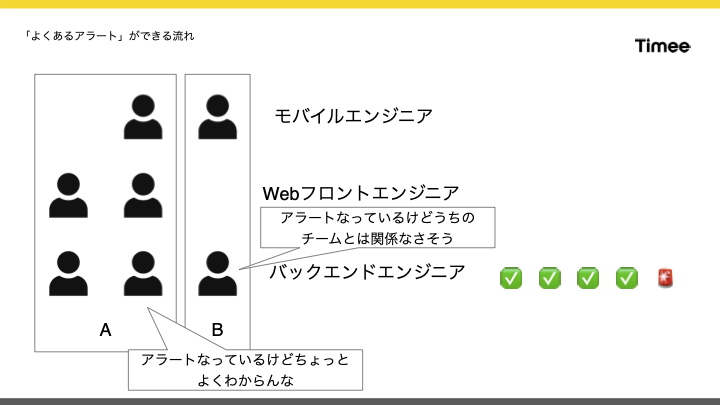
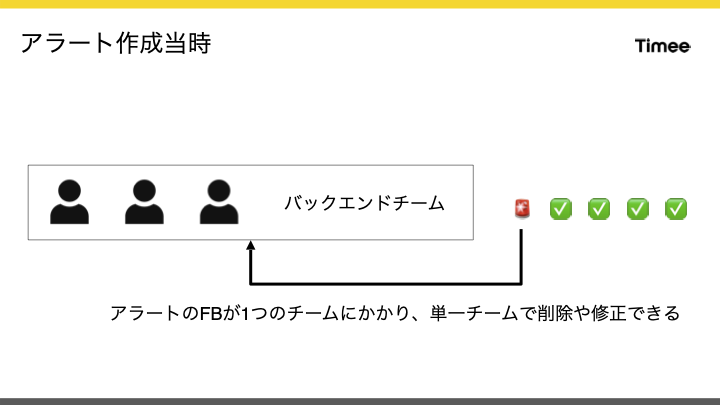
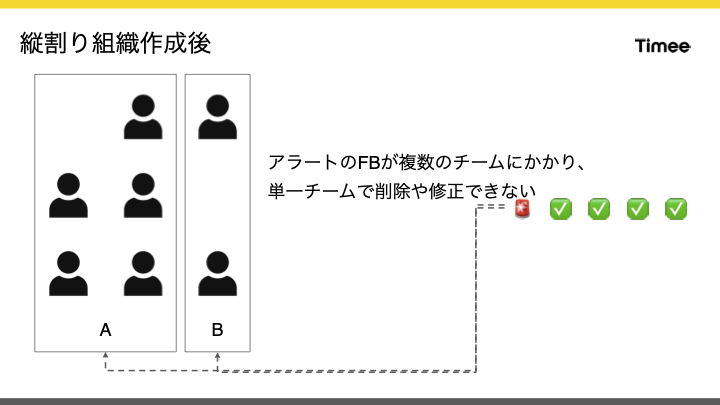
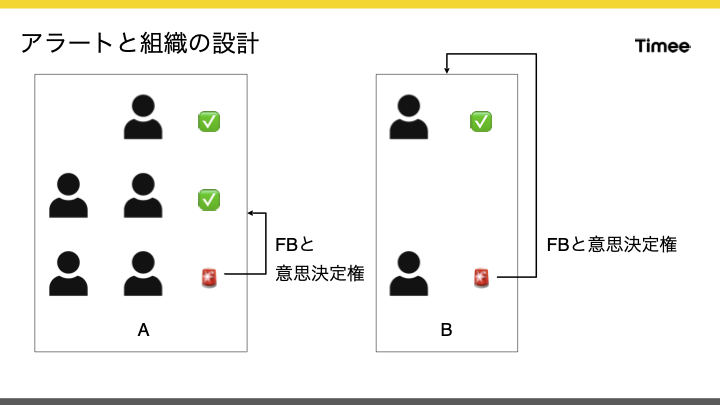
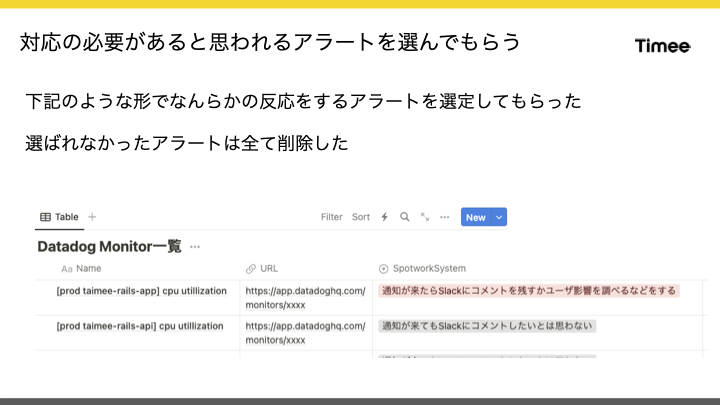
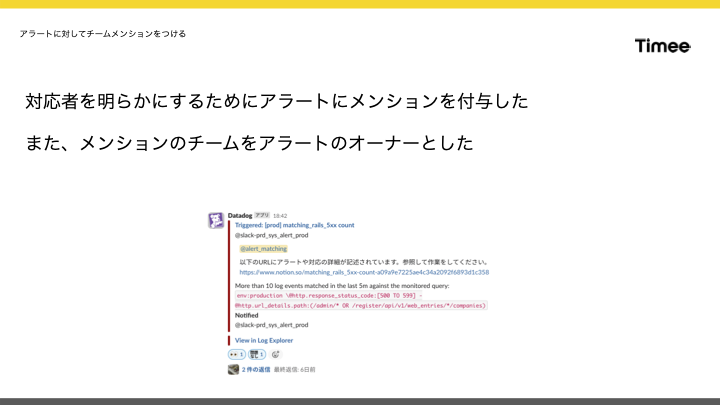
はじめに
こんにちは、株式会社タイミーの貝出と申します。データサイエンティストとして働いており、直近はカスタマーサポートの業務改善に向けたPoCやシステム開発など行っております。
さて、今回は2024年3月11日(月)~3月15日(金)に開催された「言語処理学会第30回年次大会(NLP2024)」にオンラインで参加してきましたので、参加レポートを執筆させていただきます。
言語処理学会年次大会について
言語処理学会年次大会は言語処理学会が主催する学術会議であり、国内の言語処理の研究成果発表の場として、また国際的な研究交流の場としての国内最大規模のイベントとなっています。
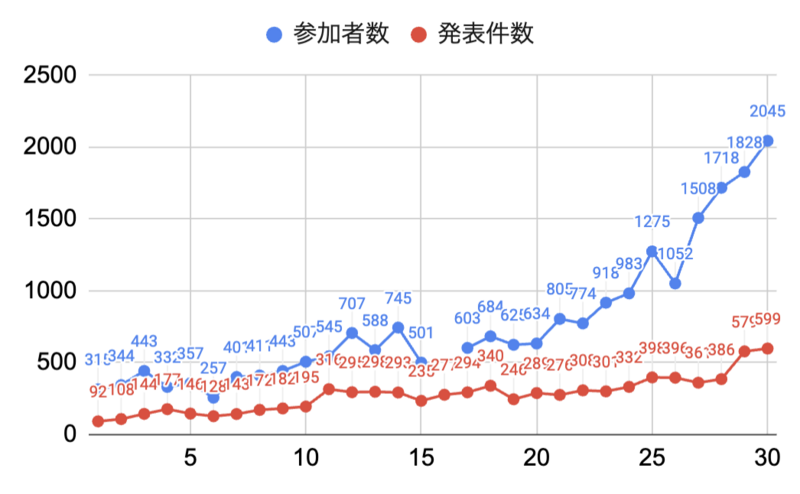
今回の年次大会は第30回を迎え、発表件数が599件、参加者数(当日参加者は除く)が2045人と大会の規模も過去最大となっており、年々大会が盛り上がっていることが伺えます。
※ 下のグラフは大会のオープニングで共有されたものです。
言語処理学会第30回年次大会に参加できなかった方でも、こちらから発表論文が閲覧できます。
興味深かった研究
初日のチュートリアルから最終日のワークショップまで興味深い発表がたくさんありましたが、個人的に気になった発表をいくつかピックアップします。
[C3-4] InstructDoc: 自然言語指示に基づく視覚的文書理解
概要
こちらの研究では、自然言語指示に基づいて文書を視覚的に理解するための基盤データセット「InstructDoc」が提案されています。InstructDocは、12種類の視覚的文書理解(VDU)タスクから構成され、多様な自然言語指示を提供する最大規模のデータセットとなっています。
研究チームでは、大規模言語モデル(LLM)の推論能力を活用し、文書のレイアウトや視覚要素を同時に理解することが可能な新しいモデル「Instruction-based Document reading and understanding model(InstructDr)」を提案し、実験を通じてその性能を検証しています。InstructDrは、自然言語指示を基に未知のVDUタスクに適応し、従来のマルチモーダルLLMの性能を超えることが確認されました。また、指示チューニング済みのモデルの重みを初期値としてFine-Tuningすることで、複数のVDUタスクで世界最高性能を達成しました。
感想
こちらの研究では視覚的文書理解の汎化性能の向上に貢献されています。自然言語指示を用いて文書画像からタスクを汎用的に実行できる技術は、社内オペレーションの様々なタスクを容易にする可能性を秘めており、今後の研究にも期待です。
NTT人間情報研究所の方による以下の過去発表資料と今回の研究はリンクする内容だと感じており、合わせて読むことで全体像がイメージしやすかったです。
Collaborative AI: 視覚・言語・行動の融合 - Speaker Deck
[A6-1] Swallowコーパス: 日本語大規模ウェブコーパス
概要
オープンな日本語言語大規模モデルの学習には、CC-100、mC4、OSCARなどのコーパスの日本語部分が用いられてきました。しかし、これらはあくまで海外で開発されたものであり、日本語テキストの品質を重視して作られたわけではありません。
そこで、研究チームは商用利用可能な日本語コーパスとしては最大のウェブコーパスを構築しました。Common Crawl のアーカイブ(2020 年から 2023 年にかけて収集された 21スナップショット分、約 634 億ページ)から、日本語のテキストを独自に抽出・精錬し、最終的には約3,121 億文字(約 1.73 億ページ)からなる日本語ウェブコーパス(Swallowコーパス)を構築しています。
Swallowコーパスは、「(1) Common Crawl の WARC ファイルから日本語テキストを抽出する。(2) 品質フィルタリングおよび重複除去で日本語テキストを厳選する。(3) テキスト内の正規化を行う。」の手順により構築されました。
Swallowコーパスを用いて Llama 2 13B の継続事前学習を行ったところ、既存のコーパスを用いた場合と比べて同等かそれを上回る性能の LLM を構築できたと報告されています。
感想
業務上LLMの日本語大規模コーパスを作ることはありませんが、自然言語処理のデータセットを作成するうえでのTipsとして大変勉強になりました。例えば、日本語判定をするためにサポートベクターマシンを学習させ fastText より高速化させた話や、MinHash による文書の重複判定など。
また、 [A8-5] では Swallow コーパスを利用した継続学習について詳しい内容が発表されており、そちらも面白かったです。
[A7-6] AmbiNLG: 自然言語生成のための指示テキストの曖昧性解消
概要
大規模言語モデル(LLM)の登場により自然言語の指示を用いた指示によって様々な言語処理タスクが実行可能になりました。しかし、これらの指示の曖昧性によりユーザの意図と異なるテキストが生成されることが問題となっています。
こちらの研究は、自然言語生成(NLG)タスクでの指示テキストの曖昧性を解消するためのベンチマークデータセットとして「AmbiNLG」が提案されました。AmbiNLG でのデータセットの作成に LLM を用いてアノテーションを行い、幅広い29のNLGタスク2000事例からなるデータセットを構築されています。また、実験により曖昧性補完の手法については、実験により複数の曖昧性カテゴリを明示的かつ組み合わせで与えることが重要であると示唆されました。
感想
LLMを使いこなすためにはプロンプトを適切に調整することが重要だと言われていますが、指示テキストの曖昧性を能動的に指摘 or 修正できるような仕組みがあれば、よりユーザーフレンドリーなLLMを構築することが可能かと思われます。個人的にも欲しい機能です!
今後の展望では、曖昧性認識・追加指示の生成・推論をend-to-end で行う対話システムの構築について言及されていたので、実際にユーザの意図をどのようにシステム側で汲み取っていくかが気になります。
おわりに
NLP2024では、他にも多数の魅力的な研究が発表され、5日間という期間が非常に充実したものとなりました。特に、大規模言語モデル(LLM)に関連する研究が目立ちましたが、その範囲はデータの構築から事実性や安全性の検証に至るまで広がっており、多様な角度からの研究成果を見ることができたのが印象的でした。
現在、タイミーでは、データサイエンスやエンジニアリングの分野で、共に成長し、革新を推し進めてくれる新たなチームメンバーを積極的に探しています!
また、気軽な雰囲気でのカジュアル面談も随時行っておりますので、ぜひお気軽にエントリーしてください。↓