こんにちは、タイミーでデータサイエンティストとして働いている小栗です。
先日、群馬大学にご招待いただき、大学生向けにキャリアに関する講演を行いました。
講演や学生との交流を行うにあたり、データサイエンティストの仕事やキャリアについて考える時間が自然と発生しました。
この記事では、学生からいただいた以下の質問をテーマに据えて、私やタイミーの事例を紹介しつつ考えてみます。
- 大企業とベンチャー企業のデータサイエンティストはどう違う?
- 未経験からデータサイエンティストを目指すには?
こんにちは、タイミーでデータサイエンティストとして働いている小栗です。
先日、群馬大学にご招待いただき、大学生向けにキャリアに関する講演を行いました。
講演や学生との交流を行うにあたり、データサイエンティストの仕事やキャリアについて考える時間が自然と発生しました。
この記事では、学生からいただいた以下の質問をテーマに据えて、私やタイミーの事例を紹介しつつ考えてみます。
こんにちは、タイミーでAndroidエンジニアをしているsyam(@arus4869)です
昨年、「チームで育てるAndroidアプリ設計」という本について、計10回にわたって輪読会を実施しました。本書は「アーキテクチャとチーム」に焦点を当てた一冊になっており、タイミーのAndroid組織の技術顧問としてさまざまなサポートをしてくださっている釘宮さん(@kgmyshin)が著者として名を連ねている本になります。
この記事では、技術顧問の釘宮さんとAndroidメンバーでの輪読会で得た学びをシェアできたらと思っています。
週に1回テーマを設けてAndroid会という勉強会を実施しています。
勉強会の中では、miroを利用した輪読会を実施しています。
輪読会は参加者の「感想」や「勉強になったこと」を共有し、「わからなかったこと」、「話してみたいこと」について議論しながら深掘りをし、学びを得ています。
セクションごとに学びがありましたが、特に実践へ応用された部分について抜粋して紹介しようと思います。
第2章の中にある多層アーキテクチャの例が非常に参考になったので、今のタイミーのアーキテクチャはどうなっているかも気になり、miroを利用した輪読会ならではの「その場で図にする」というワークを行いました。
下記は輪読会中に実際に図を描いた様子です。
タイミーでは、4層アーキテクチャから3層アーキテクチャに変遷した歴史があり、今もレガシーコードとして残っているので、新旧のアーキテクチャをREADMEに記載することにしました。この時に明確にできたおかげで、新規参画者への説明のハードルが下がり、輪読会の議論がとても良いきっかけになりました。
下記は輪読会で図にしたものを改めて整理して、READMEに記載したものです。
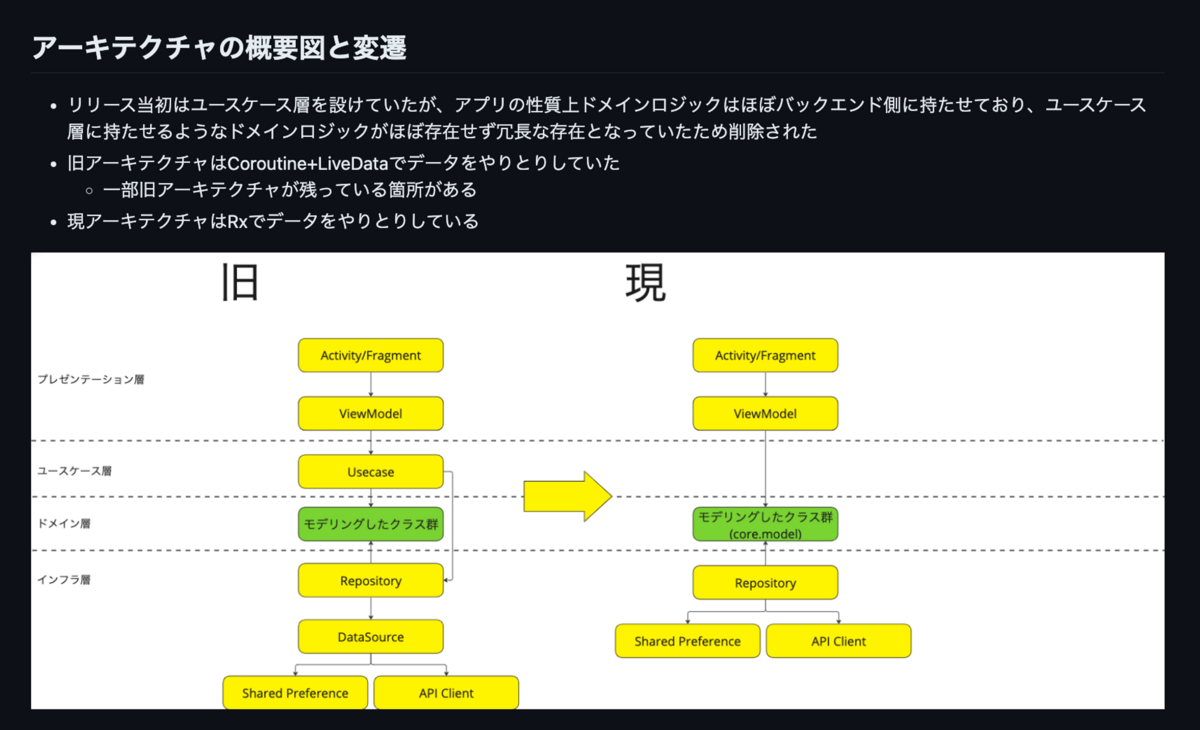
本書の第3章ではアーキテクチャの理解と適用を促進し、チームの生産性向上にどう貢献するか紹介されていました。特に理解の促進のためには、アーキテクチャの概要図やパッケージ構成、各層、クラスの説明をドキュメント化することが推奨されており、チームでもREADMEに記載することになりました。 また輪読会の中では、モジュールにも説明が必要ではないか?と議論が発展しモジュールの説明も各モジュールごとに用意することになりました。
タイミーのAndroidアプリでは、Featureごとにモジュールを分割しているので、モジュール数が多岐に渡っており、モジュールの解釈に認識齟齬が発生するリスクがありました。モジュールに対してもREADMEを記載するアプローチを生んだのは、良い議論に発展したおかげだと思います。
また、モジュールの書くべきことについては、本書に書いていない内容だったので、筆者の釘宮さんに改めて確認することができたのは、筆者が参加する輪読会ならではでとても有り難かったです。
タイミーでは定期的に輪読会を開催しております。
輪読会では、本を読んでただ学ぶだけでなく様々な議論がおこなわれ新しい洞察を発見する場となっています。
本輪読会で取り扱った「チームで育てるAndroidアプリ設計」についても新しい洞察が得られ実際に実務への応用に発展しました。是非一度よんでみてください!
少しでもタイミーに興味を持っていただける方は、ぜひお話ししましょう!
こんにちは。バックエンドエンジニアの須貝(@sugaishun)です。
今回はタイミーが本番運用しているRailsアプリケーションに対してRuby3.3.0へのアップデートを行った(YJITは引き続き有効なまま)のでその結果をご紹介したいと思います。
昨年弊社のid:euglena1215が書いたエントリーのRuby3.3.0版です。
タイミーのWebアプリケーションとしての特性は基本的には昨年と変わりありません。ですので、昨年の内容をそのまま引用させてもらいます。
タイミーを支えるバックエンドの Web API は多くのケースで Ruby の実行よりも DB がボトルネックの一般的な Rails アプリケーションです。JSON への serialize は active_model_serializers を利用しています。
今回の集計では API リクエストへのパフォーマンス影響のみを集計し、Sidekiq, Rake タスクといった非同期で実行される処理は集計の対象外としています。
今回はRuby3.2.2+YJITからRuby3.3.0+YJITへアップデートを行い、パフォーマンスの変化を確認しました。
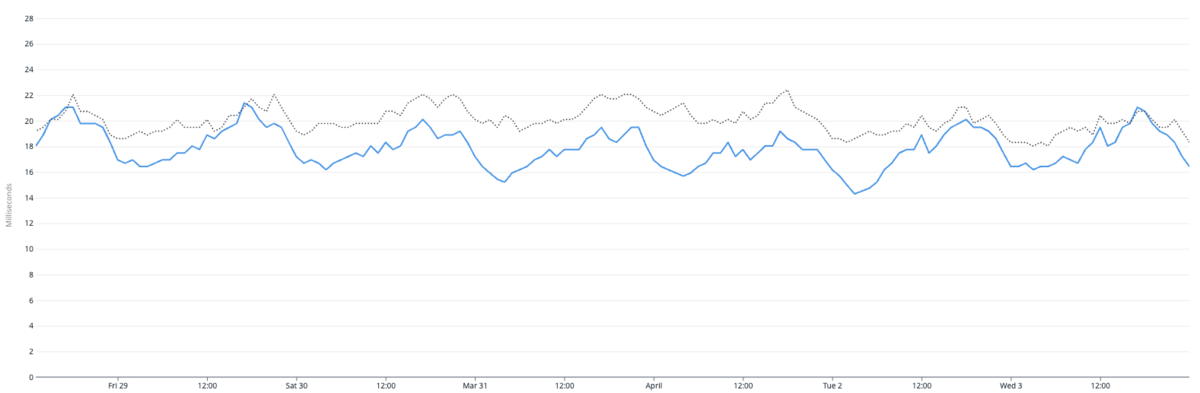
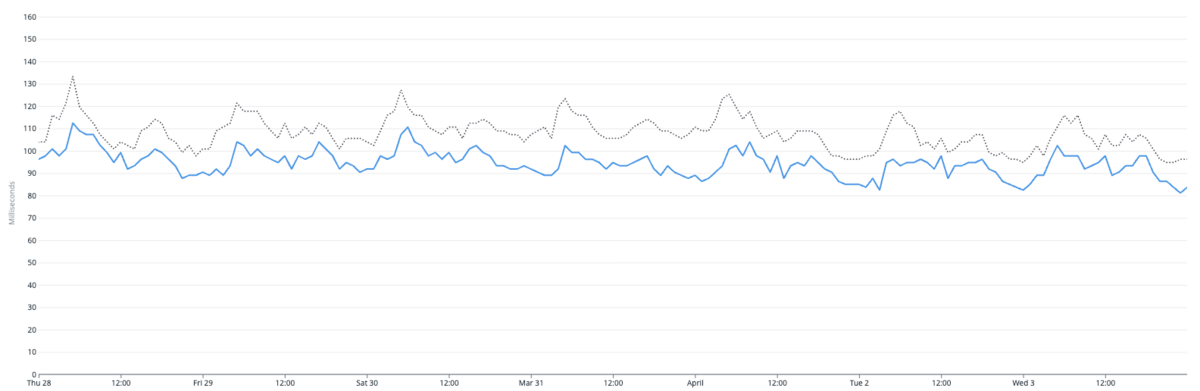
以下のグラフはAPIリクエスト全体のレスポンスタイムの50-percentileです。
グレーの点線がアップデート前の週で、青い線がアップデート後の週になります。集計した期間ではアップデート前後の平均でレスポンスタイムが10%高速化していました。
今回も前回にならってレスポンスが遅く、時間あたりのリクエスト数が多いエンドポイントに注目し、タイミーのWeb APIのうち3番目に合計の処理時間が長いエンドポイントへのパフォーマンス影響を確認しました。
以下のグラフは3番目に合計の処理時間が長いエンドポイントのレスポンスタイムの50-percentileです。こちらも同様にグレーの点線がアップデート前の週で、青い線がアップデート後の週になります。集計した期間ではアップデート前後の平均でレスポンスタイムが約12%高速化していました。
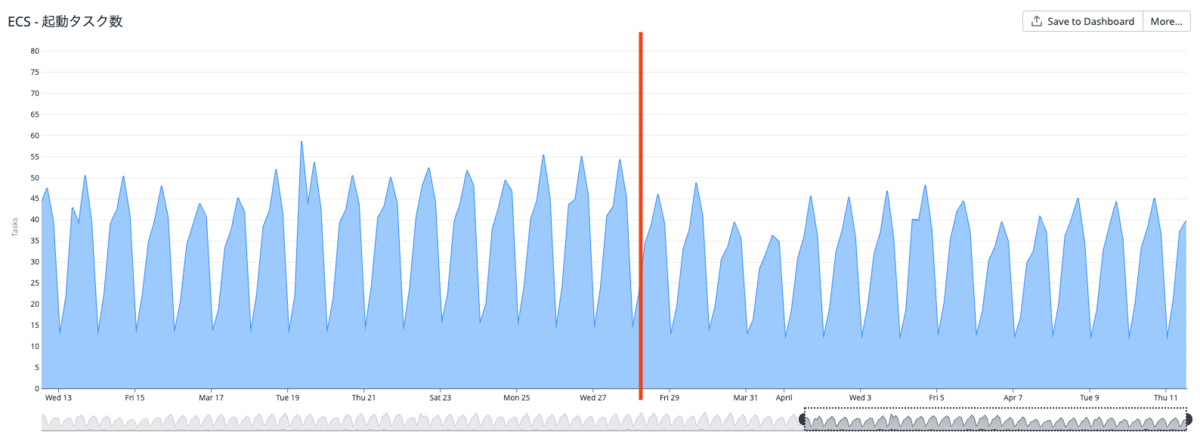
またECSの起動タスク数にも良い変化がありました。
タイミーではCPU使用率が一定の割合になるようにタスク配置する設定をしているのですが、リリース後は起動タスク数が減りました。リリース前後1週間の比較で下記のように変化しています。
このあたりはYJITの効果でリクエストに対するCPU負荷が下がった影響ではないかと推測しています。メモリ上に配置した機械語を実行するJITならでは、という感じがします。コスト的にどれだけインパクトがあるか具体的な数値は出せていませんが、パフォーマンス以外のメリットもありそうです。
と、ここまでは良かった点です。
以降では自分たちが遭遇した事象について述べたいと思います。
タイミーのRailsアプリケーションはモノリスですが、ECS上ではネイティブアプリ向けのAPIとクライアント様の管理画面向けのAPIはそれぞれ別のサービスとして稼働しています。前者のネイティブアプリ向けAPIでは特に問題なかったのですが、後者の管理画面向けAPIではメモリ使用量の最大値が約3倍超(20%弱→65%程度)になりました。以下のグラフの赤いラインがRuby3.3.0にアップデートしたタイミングになります。
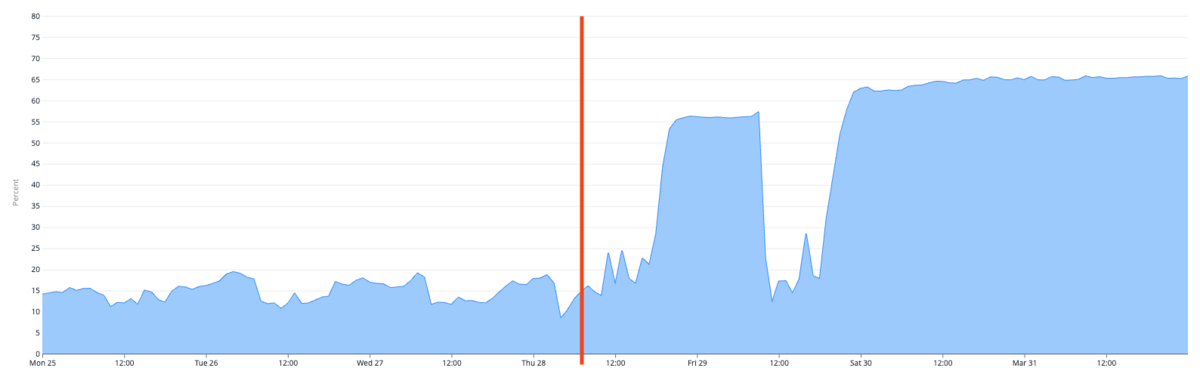
さすがに3倍超は困ったなと思い、YJITのREADMEを読んだところ下記のようにありました。
Decreasing --yjit-exec-mem-size
The
--yjit-exec-mem-sizeoption specifies the JIT code size, but YJIT also uses memory for its metadata, which often consumes more memory than JIT code. Generally, YJIT adds memory overhead by roughly 3-4x of--yjit-exec-mem-sizein production as of Ruby 3.3. You should multiply that by the number of worker processes to estimate the worst case memory overhead.We use
--yjit-exec-mem-size=64for Shopify's Rails monolith, which is Ruby 3.3's default, but smaller values like 32 MiB or 48 MiB might make sense for your application. While doing so, you may want to monitorRubyVM::YJIT.runtime_stats[:ratio_in_yjit]as explained above.
メタデータ(yjit_alloc_size)の増え方が想定以上なのではと思いつつ、ddtrace*1ではyjit_alloc_sizeは送信していないようなので、code_region_size を確認。実際、YJITのcode_region_size(JITコードのサイズ)とメモリ使用率はほぼ同じ動きをしていました。以下のグラフの左がcode_region_sizeで、右がメモリ使用率です。

というわけで--yjit-exec-mem-sizeをデフォルトの64MiBから32MiBに減らしたところ、メモリ使用量はアップデート前より少し増えた程度の水準まで抑えることができました。なお、この変更によるパフォーマンスへの影響は見られませんでした。
以下の右のグラフがメモリ使用率で、赤いラインが--yjit-exec-mem-sizeの変更をリリースしたタイミングになります。実際にメモリ使用率が下がっているのが見て取れます。

今回のメモリ使用量の大幅な増加は完全に予想外で、ステージング環境でもメモリ使用量の変化はウォッチしていましたが、特に大幅な増加は見られず本番環境で初めて発覚する事態になりました。すでにRuby3.2系でYJITを有効にしているプロダクトでも、Ruby3.3.0+YJITにアップデートされる際には--yjit-exec-mem-sizeの値には注意したほうが良さそうです。
Ruby3.2ですでにYJITを有効にしているプロダクトでもRuby3.3.0にアップデートしてパフォーマンスの改善が見られました(YJITの影響なのかそれ以外の最適化による恩恵なのかまでは検証しておりません)。
すでにYJITを有効にしていた場合でもRuby3.3.0へのアップデートでメモリの使用量が大幅に増加する可能性があるので注意しましょう。
調査の際には下記の(主にk0kubunさんの)ドキュメントに非常に助けられました。この場を借りてお礼を申し上げます。
本エントリーがこれからRuby3.3.0+YJITへアップデートされる方のお役に立てば幸いです。
*1:タイミーはDatadogを使っています。ddtraceはDatadogにメトリクスを送信するgemです
2024年2月21日に「GENBA #2 〜Front-End Opsの現場〜」と題してタイミー、Sansan、ココナラ、X Mileの4社でFront-End Opsに関する合同勉強会を開催しました。 今回はそちらの勉強会からタイミーフロントエンドエンジニアの西浦太基さんの発表をイベントレポートでお伝えします。

こんにちは、西浦 太基です。家族で北海道札幌市で暮らす33歳です。 Javaでキャリアをスタートし、今はフロントエンドエンジニアとして3年目になります。趣味はカレー作りとゲームです。
本日は「いつか来たる大改修のために備えておくべきこと」について、実際に大きな改修を経験して学んだこと、泥臭い現場の話や反省点を、エピソードベースでシェアします。

店舗向けの管理画面をシングルページアプリケーション(SPA)へ移行する改修でした。もともとサーバーサイドレンダリング(SSR)で構築されていたシステムを、ReactとNext.jsを使用したSPAに段階的にリプレイスしていきました。改修した機能は大きく下記3つです。

既存機能の仕様調査に苦労 既存のSSR画面の詳細なドキュメントが残っておらず、非常に苦労しました。これは、タイミー入社前のSler時代もよく経験したことで、 “あるある” なのですが、状況を打開するためには非常に泥臭い調査が必要です。もちろんドキュメントが全く残っていないわけではなく、Figma や Notion に部分的に残されてはいたのですが、完全にはカバーされていません。おまけにソースコードの情報が必ずしも正確でないこともあり、かなりの時間と労力をかけ、調査を行いました。

ユニットテストはコンポーネント単位で存在していましたが、E2E自動化の仕組みが存在しませんでした。VRT(Visual Regression Testing)は、Storybook を用いて行われていたのですが、今回のプロジェクトの規模や顧客への影響を考えると、軽い検証を行うだけではリスクが大きいと判断し、結果的に 431件の E2Eテストを手動で泥臭く実施する道を選びました。

当時のフロントエンドチームはレビュー体制の整備が不十分で、メンバーも限られており、レビューコストが高くなってしまいました。チームは僕を含めてわずか2人と、非常勤の業務委託1人。レビューに十分な時間を確保するのが難しく、プロジェクトの進行に影響が出ていました。そのため、レビューを効率的に進めるために、一人のエンジニアの時間をまとめて確保し、一気にレビューを完了させる方法を取りました。本来は、フルリモートでの非同期レビューを行える体制が理想的だと思います。

機能の仕様は背景込みで残しておく 詳細なソースコードコメントや定義書があれば、将来の改善に役立ちます。特に複雑な機能や多くの入力項目を持つ場合、実装の背景を理解することで、後々の改善が容易になり、属人化を避けることができます。最近は、Figma や Notion に仕様と背景を含めて記録するよう心がけています。

これまでUTやVRTが充実していれば、そこまでE2Eは重要ではないと考えていました。しかし、今回のリプレイスを経て、自動化テストの重要性を再認識しています。E2Eによって、UTで検知できない問題をリリース前に特定できることがあり、改めてE2Eの重要性と自動化の利点を実感しました。
レビュー文化をしっかり根付かせつつ、レビューのポイントをチーム内でしっかりドキュメント化しておくことが大事です。ドキュメント化してないと、都度のすり合わせで時間を取られ、レビューコストが増えます。その結果、リリースサイクルも遅れたりするわけです。現在はフロントエンドチームの拡大もあり、レビュールールを明文化する作業を進めています。

私がSler時代に直面した、「ソースコードを見なければ仕様が理解できない」といった “あるある” な内容も含め、日頃から大きなリプレイスに向けた心構えや備えが必要性を共有できたら嬉しいです。泥臭い作業を発見したら、悲観的になるのではなく「これは考え直すタイミングだな」というマインドを持つことも大切かと思います。
こんにちは、株式会社タイミーの貝出と申します。データサイエンティストとして働いており、直近はカスタマーサポートの業務改善に向けたPoCやシステム開発など行っております。
さて、今回は2024年3月11日(月)~3月15日(金)に開催された「言語処理学会第30回年次大会(NLP2024)」にオンラインで参加してきましたので、参加レポートを執筆させていただきます。
言語処理学会年次大会は言語処理学会が主催する学術会議であり、国内の言語処理の研究成果発表の場として、また国際的な研究交流の場としての国内最大規模のイベントとなっています。
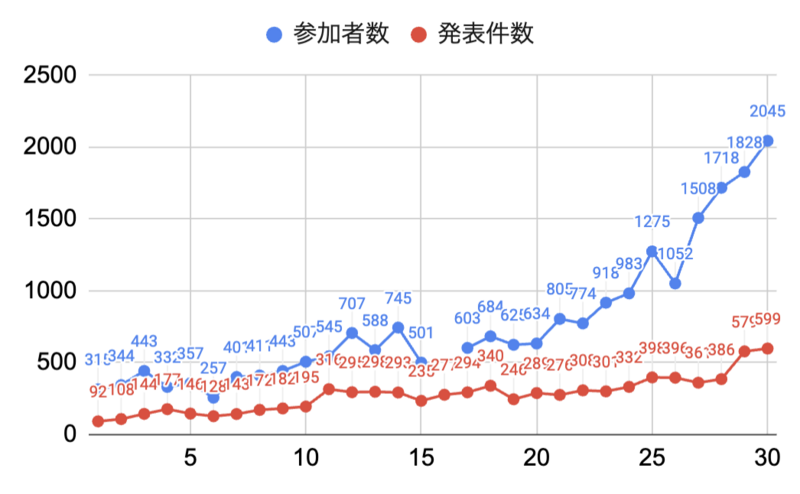
今回の年次大会は第30回を迎え、発表件数が599件、参加者数(当日参加者は除く)が2045人と大会の規模も過去最大となっており、年々大会が盛り上がっていることが伺えます。
※ 下のグラフは大会のオープニングで共有されたものです。
言語処理学会第30回年次大会に参加できなかった方でも、こちらから発表論文が閲覧できます。
初日のチュートリアルから最終日のワークショップまで興味深い発表がたくさんありましたが、個人的に気になった発表をいくつかピックアップします。
こちらの研究では、自然言語指示に基づいて文書を視覚的に理解するための基盤データセット「InstructDoc」が提案されています。InstructDocは、12種類の視覚的文書理解(VDU)タスクから構成され、多様な自然言語指示を提供する最大規模のデータセットとなっています。
研究チームでは、大規模言語モデル(LLM)の推論能力を活用し、文書のレイアウトや視覚要素を同時に理解することが可能な新しいモデル「Instruction-based Document reading and understanding model(InstructDr)」を提案し、実験を通じてその性能を検証しています。InstructDrは、自然言語指示を基に未知のVDUタスクに適応し、従来のマルチモーダルLLMの性能を超えることが確認されました。また、指示チューニング済みのモデルの重みを初期値としてFine-Tuningすることで、複数のVDUタスクで世界最高性能を達成しました。
こちらの研究では視覚的文書理解の汎化性能の向上に貢献されています。自然言語指示を用いて文書画像からタスクを汎用的に実行できる技術は、社内オペレーションの様々なタスクを容易にする可能性を秘めており、今後の研究にも期待です。
NTT人間情報研究所の方による以下の過去発表資料と今回の研究はリンクする内容だと感じており、合わせて読むことで全体像がイメージしやすかったです。
Collaborative AI: 視覚・言語・行動の融合 - Speaker Deck
オープンな日本語言語大規模モデルの学習には、CC-100、mC4、OSCARなどのコーパスの日本語部分が用いられてきました。しかし、これらはあくまで海外で開発されたものであり、日本語テキストの品質を重視して作られたわけではありません。
そこで、研究チームは商用利用可能な日本語コーパスとしては最大のウェブコーパスを構築しました。Common Crawl のアーカイブ(2020 年から 2023 年にかけて収集された 21スナップショット分、約 634 億ページ)から、日本語のテキストを独自に抽出・精錬し、最終的には約3,121 億文字(約 1.73 億ページ)からなる日本語ウェブコーパス(Swallowコーパス)を構築しています。
Swallowコーパスは、「(1) Common Crawl の WARC ファイルから日本語テキストを抽出する。(2) 品質フィルタリングおよび重複除去で日本語テキストを厳選する。(3) テキスト内の正規化を行う。」の手順により構築されました。
Swallowコーパスを用いて Llama 2 13B の継続事前学習を行ったところ、既存のコーパスを用いた場合と比べて同等かそれを上回る性能の LLM を構築できたと報告されています。
業務上LLMの日本語大規模コーパスを作ることはありませんが、自然言語処理のデータセットを作成するうえでのTipsとして大変勉強になりました。例えば、日本語判定をするためにサポートベクターマシンを学習させ fastText より高速化させた話や、MinHash による文書の重複判定など。
また、 [A8-5] では Swallow コーパスを利用した継続学習について詳しい内容が発表されており、そちらも面白かったです。
大規模言語モデル(LLM)の登場により自然言語の指示を用いた指示によって様々な言語処理タスクが実行可能になりました。しかし、これらの指示の曖昧性によりユーザの意図と異なるテキストが生成されることが問題となっています。
こちらの研究は、自然言語生成(NLG)タスクでの指示テキストの曖昧性を解消するためのベンチマークデータセットとして「AmbiNLG」が提案されました。AmbiNLG でのデータセットの作成に LLM を用いてアノテーションを行い、幅広い29のNLGタスク2000事例からなるデータセットを構築されています。また、実験により曖昧性補完の手法については、実験により複数の曖昧性カテゴリを明示的かつ組み合わせで与えることが重要であると示唆されました。
LLMを使いこなすためにはプロンプトを適切に調整することが重要だと言われていますが、指示テキストの曖昧性を能動的に指摘 or 修正できるような仕組みがあれば、よりユーザーフレンドリーなLLMを構築することが可能かと思われます。個人的にも欲しい機能です!
今後の展望では、曖昧性認識・追加指示の生成・推論をend-to-end で行う対話システムの構築について言及されていたので、実際にユーザの意図をどのようにシステム側で汲み取っていくかが気になります。
NLP2024では、他にも多数の魅力的な研究が発表され、5日間という期間が非常に充実したものとなりました。特に、大規模言語モデル(LLM)に関連する研究が目立ちましたが、その範囲はデータの構築から事実性や安全性の検証に至るまで広がっており、多様な角度からの研究成果を見ることができたのが印象的でした。
現在、タイミーでは、データサイエンスやエンジニアリングの分野で、共に成長し、革新を推し進めてくれる新たなチームメンバーを積極的に探しています!
また、気軽な雰囲気でのカジュアル面談も随時行っておりますので、ぜひお気軽にエントリーしてください。↓
こんにちは、iOSエンジニアの前田(@naoya_maeda) 、早川(@hykwtmyk)、三好、岐部(@beryu)、Androidエンジニアのみかみ(@mono33)です。
2024年3月22-24日に渋谷で開催されたtry! Swift Tokyoに、タイミーもGOLDスポンサーとして協賛させて頂きました。
私達もイベントに参加したので、メンバーそれぞれが気になったセッションを紹介します。
僕が特に気になったセッションは、リルオッサさんによる「SF Symbolsの芸術的世界:限りない可能性を解き放つ」です。
リルオッサさんは、iOSDC Japan 2022でもSF Symbolsアートの可能性についてお話されており、今回のセッションでは、アニメーションを交えたダイナミックなSF Symbolsアートを紹介されていました。
SF Symbolsは、Appleが提供するアイコンおよびシンボルのセットです。
WWDC 2019で初めて開発者に公開され、iOS 、macOS、watchOSで使用可能になりました。
SF Symbolsは、定期的にアップデートが行われ、新しいアイコンやシンボルの追加、パフォーマンスの改善が行われています。
SF Symbols 5では、5000を超えるアイコンおよびシンボルが提供されています。さらに、わずか数行のコードでアニメーションエフェクトを実現することができるようになりました。

「SF Symbolsの芸術的世界:限りない可能性を解き放つ」では、さまざまなアイコンやシンボル、そしてSF Symbols 5で追加されたアニメーション機能をフルに活用し、ダイナミックなSF Symbolsアート作品が紹介されています。
普段何気なく使用しているSF Symbols達が組み合わされていき、一つのSF Symbolsアート作品になる様は圧巻でした!
また、SF Symbols 5には、様々なアニメーションエフェクトが用意されていると知ることができ、タイミーアプリ内でもSF Symbolsを活用していきたいと感じました。
今回ご紹介しきれなかった作品はGitHubで公開されているので、ぜひ一度ご覧ください!
今回、自分が気になったセッションは「コード署名を楽しく乗り切る方法」です。
このセッションではCertificate、Provisioning Profile、Application Identifierなど、アプリをリリースする上で必要なコード署名の要素を分かりやすくパズルに見立てて解説していました。

また、パズルに見立てることによってどこにエラーが起きているのかが分かりやすくなり解決するための要素の推測も容易になったかなと思います。
下の図で言うとProvisioning ProfileはCertificateとは問題なく結びついていますが、Application Identifierと正しく結びついていないためエラーが起きています。
解決するには「Provisioning Profileに結びついているApplication Identifierと一致するようにアプリ側のApplication Identifieを設定しなおす」か、「Provisioning Profileをアプリ側に設定されているApplication Identifierに合わせて作成しなおす」かになります。

各要素をパズルのピースに見立てることで、相互の結びつきが視覚的に解像度高く理解できました。
登壇者のJosh Holtzさんの発表内容も相まってコード署名を楽しく感じることができました笑
特に印象に残ったセッションは「マクロをテストする」です。今回のtry! Swiftでも注目を集めていたTCAを開発する、Point-FreeのStephenさんとBrandonさんによる発表です。
マクロはSwift 5.9から導入されたコンパイル時にソースコードの一部を生成する機能です。主にボイラープレートを減らすことを目的に利用されます。iOSアプリ開発の世界ではSwiftUIのプレビューを簡潔に行う「#Preview」や新しいデータ永続化のフレームワークであるSwiftDataのモデル定義を簡略化する「@Modelマクロ」などの標準のマクロが数多く用意されています。
マクロは有益ではあるもののマクロによって生成されるコードが多ければ多いほどエラーが発生する可能性は高まります。特にマクロを実装する場合は生成されるコードも対象に、Swiftの文法のあらゆるエッジケースを考慮して多くのテストを行うことが望ましいです。
しかし、マクロのテストも多くの課題があります。例えばマクロで生成されたコードのエラーや警告がXcode上からわかりにくく、 Apple標準のマクロのテストヘルパーの文字比較の判定がシビアでフォーマットなどの本質的ではない部分でテストが落ちてしまうという問題があります。また、マクロの実装が変わった場合はテストを修正する必要がありメンテナンスも大変です。
そこでPoint-Freeがswift-macro-testingというテストライブラリを公開しています。swift-macro-testingは検証したいマクロのソースコードをassertMacro()に書き込むだけでどのように展開されるかを自動でテストコードに反映します。
途中でライブデモがあったり、黒魔術的に生成されるテストコードを披露されたりとなんとなく会場も賑わっていた気がします。Androidにおいて自動生成を行うコードはたまに書くのですが、自動生成のコードをテストするというのは個人的に盲点で面白いなと思いました。
今回気になったセッションは、平和に大規模なコードベースを移行する方法です。
数あるセッションの中では、割と実用的ですぐに活用できるような内容でした。
セッション資料はこちら
@_disfavoredOverload等存在自体知らなかったので、とても勉強になりました。
来年の開催すると思うので、ぜひ皆さんも参加してみてください。
try! Swiftは4回目(2016,2018,2019,2024)の参加でした(2017年の記憶が曖昧なので、5回目かもしれない…)。
どのセッションも有意義でしたが、私は特に「Accessibility APIを使ってアプリケーションを拡張する」のセッションが非常に興味深く、サンプルアプリまで作りました。
1分にまとめたショート動画を用意したのでご覧ください。
時間の関係で動画中では詳細に触れていませんが、Accessibility APIを通して取得できる AXUIElement インスタンスには大きな可能性を感じました。このクラスのインスタンスには起動中の全アプリについての以下のようなウィンドウ情報が詰まっています。
他のアプリのUIに自分のアプリが直接的に作用できるこの考え方は、Sandboxのcapabilityを取り除けるmacOSならではでとても面白いと感じました。
実際にユーティリティアプリ作る際は、以下のような手順で行いました。
以下のGitHubリポジトリで公開してあるので、ぜひ触ってみてください。
(あくまで検証用で作ったので粗は多いと思います…。PRもお待ちしております)
try!Swiftは世界中からiOSエンジニアが集まるイベントなので久しい友人に会えるのはもちろん、タイミーのエンジニアはフルリモートで働いているので普段WEBカメラ越しにしか話していない同僚とも対面で会話できて非常に楽しい期間でした。 この場を用意してくださった運営チームの皆さん、および会場でお話ししてくださった皆さんに心から感謝します。
上記で紹介したセッション以外にも非常に興味深いセッションが多くありました。 記事にある内容や、その他の内容についても、もしタイミーのエンジニアと話したいという方がいらっしゃればぜひお気軽にお話ししましょう!
タイミーの矢尻、須貝、razです。
ソフトウェアテストに関する国内最大級のカンファレンス「JaSST (Japan Symposium on Software Testing) ‘24 Tokyo」が2024/03/14、15の2日間にわたって開催されました。


今回は我らがGo AkazawaとYorimitsu Kobayashiも登壇!その応援も兼ねてQAコーチ、エンジニア、スクラムマスターの3名が参加。世界中で開催されるすべての技術系カンファレンスに無制限で参加できる「Kaigi Pass」という制度を利用しました。
本レポートでは、印象に残ったセッションの内容を中心に、2日間の会の様子をお伝えします。
今年の1月に入社したばかりの駆け出しQAコーチの矢尻です。
毎年楽しみにしているJaSST Tokyoに今年もオンライン視聴で参加しました。
視聴したすべてのセッションが示唆に富んだ学び多きものでしたが、中でもインパクトの大きかったGojko Adzic 氏による基調講演「Tangible software quality」の感想をお話します。
「Tangible software quality」を直訳すると、「具体的なソフトウェア品質」となります。
このセッションでは直接的にテストできないソフトウェア”品質”をプロダクトに”作り込む”ためのマインドセットやモデルが紹介されました。
セッションの最後に紹介された5つの「Making Quality Tangible(品質を具体化するためのガイドライン)」は、哲学的で難解ですが、噛みしめるほどに味わい深いものでしたので私なりに意訳して感想に代えさせていただきます。
Shape priorities with a MODEL(意訳:モデルを用いて優先度を形成せよ) 製品の意思決定の一環として生じるトレードオフを判断する基準として勘は通用しません。ここでシンプルで有用なモデルとして「有用性」「差別化」「飽和点」から成るQUPER Modelと「マズローの5段階欲求モデル」が紹介されていました。
VISUALISE and ACT(視覚化して行動せよ) もうこれは字面通り「収集したメトリクスを根拠に行動せよ」ということかと思います。 (そういえば最近「見える化」って聞かなくなりましたね)
まさにタイミーでも価値あるソフトウェアを最速でデリバリーするためにチームトポロジー型の組織戦略を採用しています。価値に着目している点で同じ方向性のセッションだと感じましたので、今回紹介されたモデルやメトリクスは折に触れてチームで紹介し試していけたらと考えています。
自動テストが好きなバックエンドエンジニアの須貝です。
JaSSTは初参加(オンライン視聴)でして、弊社の赤澤と小林の登壇を応援しようというのがきっかけでした。
全体を通して一番印象に残ったのはトヨタ自動車の長尾洋平氏による「自動車のソフトウェア品質に関する現場の試行錯誤」です。
自動車を制御するソフトウェアは数千万から数億行のコードからなっており、まずその規模と複雑さに驚きました。また、テストコードの品質にも規格があり、その質を担保するためにミューテーション分析などを活用しているそうです。
一方で実機テストの制約の多さに苦労されているとのことでこれは自動車ならではの悩みだなと思いました。テストのアプローチとしてQAが要件定義段階から関与するいわゆるシフトレフトを実践されている点も非常に興味深かったです。
また他のセッションですと「音楽の世界から学ぶ、ソフトウェア品質」は、プロ演奏者を招いて音楽とソフトウェアという無形のプロダクトの質について探る野心的な試みでした。
私はソフトウェアエンジニアという立場ですが、日々の開発では自身でもテストを行っているため、大変学びの多いイベントでした。
QAやテスト界隈がどんな感じなのか気になったので参加しましたスクラムマスターのrazです。
私もJaSSTに初参加(オンライン)でした。正直なところ、社内で参加希望者を募るまで、存在も知らなかったのですが、参加できてよかったです。
私も印象に残ったのは、トヨタ自動車の長尾洋平氏による「自動車のソフトウェア品質に関する現場の試行錯誤」なのですが、須貝さんが感想を書いてくださってるので割愛しておきます笑。
色々な発表を見させていただきましたが、全体的な感想として「アジャイル」や「スクラム」といったキーワードがたくさん出ていたのが驚きでした。ソフトウェアエンジニアがアジャイルなプロダクト開発に変化していった中で、QA組織やQAエンジニアがその変化へ適応していこうとしているように感じました。
その中でも「品質」について「誰のなんのための品質なのか」を考えているのが、とても良かったです。発表の中には「本当にその考えでいいのか?」という議論の余地はあったかもしれませんが、顧客中心に品質を議論する活動、それを継続するのは素晴らしいことだと思います。
弊社でも「顧客のための品質」について、もっと考えていければと思います。
弊社は今回ゴールドスポンサーとして初めてJaSST Tokyoに協賛させていただきました。次回以降もなんらかの形で貢献して一緒にコミュニティを盛り上げていければと思います。
また、弊社ではQA、SETの採用も積極的に行っております。
タイミーのQA、ソフトウェアテストについてもっと知りたいという方はぜひカジュアル面談でお話しましょう。